Amazon EC2 - Failure Recovery using CloudEndure
Scalable and Cost-Effective Business Continuity for Physical, Virtual, and Cloud Servers
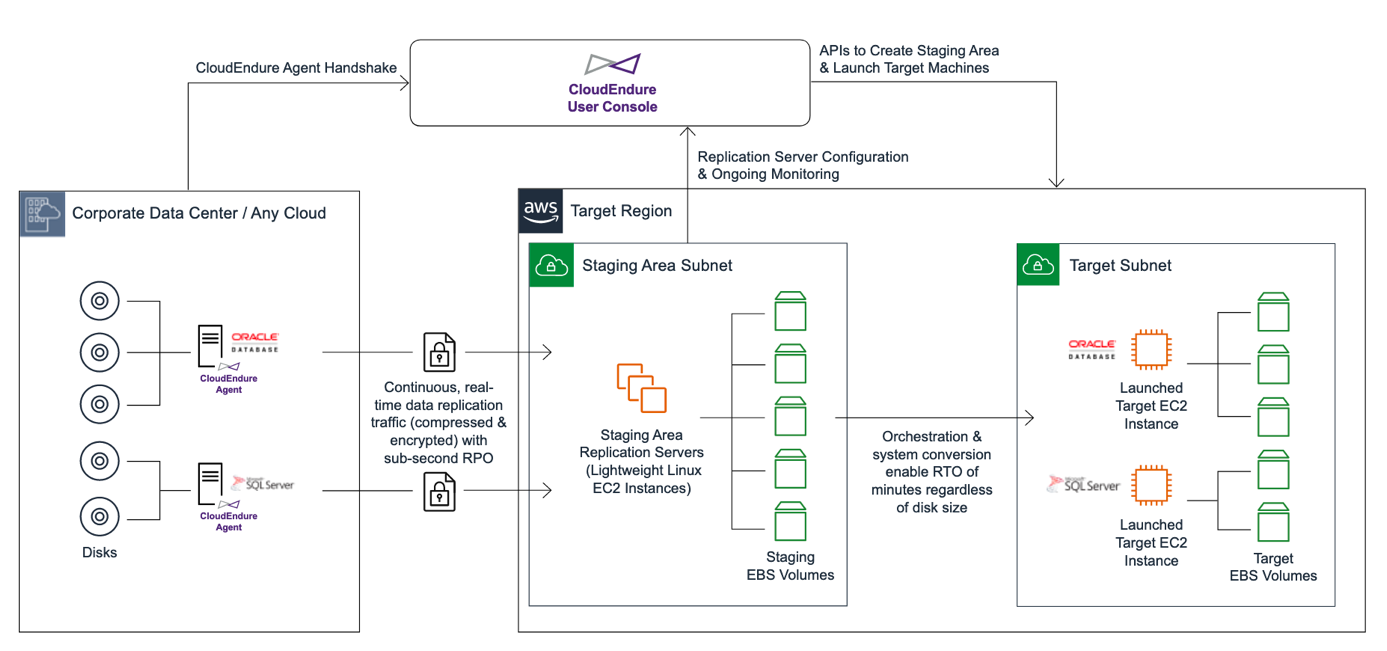
IT disasters, such as data center failures, server corruption, or cyber attacks, can not only disrupt your business but also cause data loss, affect revenue, and harm reputation. CloudEndure Disaster Recovery minimizes downtime and data loss by providing fast and reliable recovery of physical, virtual, and cloud-based servers on AWS. You can use CloudEndure Disaster Recovery to protect your most critical databases, including Oracle, MySQL, and SQL Server, as well as enterprise applications such as SAP. CloudEndure Disaster Recovery continuously replicates your machines (including the operating system, a system status setting, databases, applications, and files) into a low-cost staging area in your AWS account and a preferred region. In the event of a disaster, you can instruct CloudEndure Disaster Recovery to automatically start thousands of your machines in their fully provisioned state in minutes. By replicating your machines to a low-cost temporary storage area while being able to launch fully provisioned machines in minutes, CloudEndure Disaster Recovery can significantly reduce the cost of the disaster recovery infrastructure.
How does it work?
Continuous Data Replication
CloudEndure Disaster Recovery provides continuous, asynchronous, block-level replication of your origin machines over an area of scale. This allows you to achieve secondary recovery point objectives (RPOs), as updated applications are always ready to be adapted on AWS in the event of a disaster.
Low cost scale area
Data is continuously kept in sync and a light scale area in your target AWS region. The scale area contains low-cost features that are automatically provided and managed by CloudEndure Disaster Recovery. This eliminates the need for duplicate resources and significantly reduces your total cost of ownership (TCO) from disaster recovery.
Automated machine conversion and orchestration
In the event of a disaster or testing, CloudEndure Disaster Recovery triggers a highly automated machine conversion process and a scalable orchestration engine that quickly processes thousands of machines in the AWS target region in parallel. This allows you to achieve recovery time objectives (RTOS) in minutes. Unlike other application-level solutions, CloudEndure Disaster Recovery replicates entire machines, including OS, system state configuration, system disks, databases, applications, and files. So when you start your machines during a failure or test, your machines will work exactly as they do it on your source infrastructure. You don’t need to install everything new or keep duplicate copies of OS, system state configuration, or software.
Point-in-time recovery
Granular point-in-time recovery allows you to recover applications and IT environments that have been corrupted as a result of accidental system changes, ransomware, or other malicious attacks. In these cases, you can launch applications from a consistent previous point instead of launching applications in their most up-to-date state. During recovery, you can select the last state or a previous state from a list of points in time.
Easy, non-disruptive testing
With CloudEndure Disaster Recovery, you can conduct disaster recovery tests without disrupting your source environment or without the risk of losing data. During testing, CloudEndure Disaster Recovery processes machines in the target AWS Region in complete isolation to avoid network conflicts and performance impact. Because you’re leveraging AWS, there’s no need to provision or prepay for the resources you need during the disaster recovery survey. The automation of CloudEndure Disaster Recovery also minimizes the manual labor required for testing.
Comprehensive application and infrastructure support
Because CloudEndure Disaster Recovery replicates data at the block level, you can use it for all applications and databases that work on supported versions of Windows and Linux OS. This includes Windows Server versions 2003/2008/2012/2016/2019 and Linux distributions such as CentOS, RHEL, OEL, SUSE, Ubuntu, and Debian.
For more information see the article: AWS CloudEndure - How CloudEndure Disaster Recovery Works
References