Disaster Recovery Strategies
Having a disaster recovery plan is more than having backup routines and redundant components. You should define what your RTO and RPO objectives are for disaster recovery. Set objectives based on business metrics.
Set objectives, within what is acceptable for your application, about time downtime and loss of data.
Defining the Recovery Time Objective (RTO) and Recovery Point Objective (RPO) for each application, you’ll have how to guide your decisions on which disaster recovery strategies to follow.

Recovery Time Objective (RTO) is the maximum acceptable delay between service interruption and service restoration. This determines what is considered an acceptable time window when the service is unavailable.
Recovery Point Objective (RPO) is the maximum acceptable time since the last data recovery point. This determines what is considered an acceptable loss of data between the last recovery point and the service outage.
Each service has a Service Level Agreement (SLA). If you’re looking for a uptime higher than that defined by AWS or need to minimize risk of failures in a region, then define a recovery strategy Multi-Region.
Strategies can be defined at different levels of your architecture, such as software components, hardware, networks, availability zones, etc. Multi-Region, you should choose one of the following strategies. They are listed in increasing order of complexity and descending of RTO and RPO.
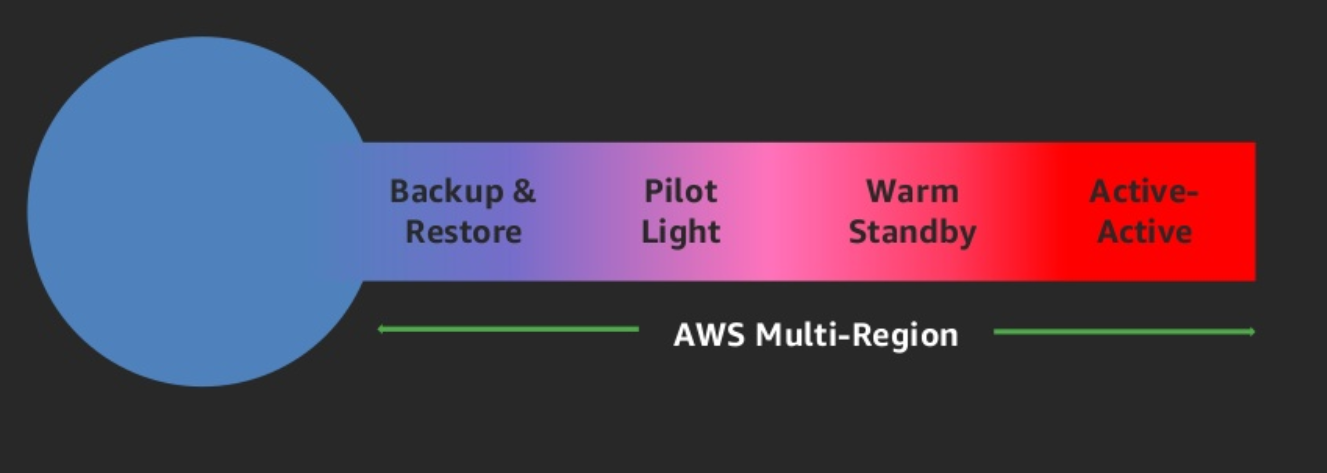
Backup & Restore (RPO in hours, RTO in 24 hours or less): Back up your data and applications in the DR. Region Restore this data when needed to recover from a disaster.
Pilot Light (RPO in minutes, RTO in hours): Keep a minimal version of an environment by always running the most critical core elements of your system in the DR. region At the time of performing the recovery, you can quickly provision a full-scale production environment that includes that critical core.
Warm Standby (RPO in seconds, RTO in minutes): Keep a reduced version of a fully functional environment always running in the DR region. Business critical systems are fully duplicated and are always on, but with a reduced fleet. When the time comes for recovery, the system scales quickly to process the production load.
Active-Active (RPO is none or possibly seconds, RTO in seconds): Your workload is deployed and actively serves traffic from multiple AWS regions. This strategy requires you to synchronize users and data between the regions you’re using. When recovery time comes, use services such as Amazon Route 53 or AWS Global Accelerator to route user traffic to the entire workload location.
**Seek to automate every step of your tests as much as possible:**
- Environment Fault Injection
- Failover Actions (procedure for using the secondary environment)
- Failback Actions (Procedure for Returning the Use of the Primary Environment)
- Monitoring All Steps
Avoid recovery mechanisms that are not often tested. Define regular tests for failover to ensure expected RTO and RPO are met
References: