Amazon Aurora - Global Database
Objetivo
Esses exercícios irão mostrar os passos para o uso do mecanismo Global Database para bases de dados do Amazon Aurora for MySQL. Caso queira mais informações clique aqui.
Ao final desse exercício, você será capaz de:
- Criar clusters de banco de dados
- Monitorar o desempenho da replicação
- Realizar a operação de failover entre regiões
Tempo de Execução Estimado: 2 horas
Custo Aproximado: 20 USD
Crie um Aurora Global Database
Amazon Aurora Global Database foi projetado para aplicações distribuídas globalmente, permitindo que um único banco de dados Amazon Aurora abranja várias regiões da AWS. Ele replica seus dados sem impacto no desempenho do banco de dados, permite leituras locais rápidas com baixa latência em cada região e fornece recuperação de desastres de interrupções em uma região.
Este laboratório contém as seguintes tarefas:
- Crie um ambiente de laboratório na Região Ohio (us-east-2)
- Crie um ambiente de laboratório na Região Virginia (us-east-1)
- Crie um Aurora global cluster
1. Crie um ambiente de laboratório na Região Ohio (us-east-2)
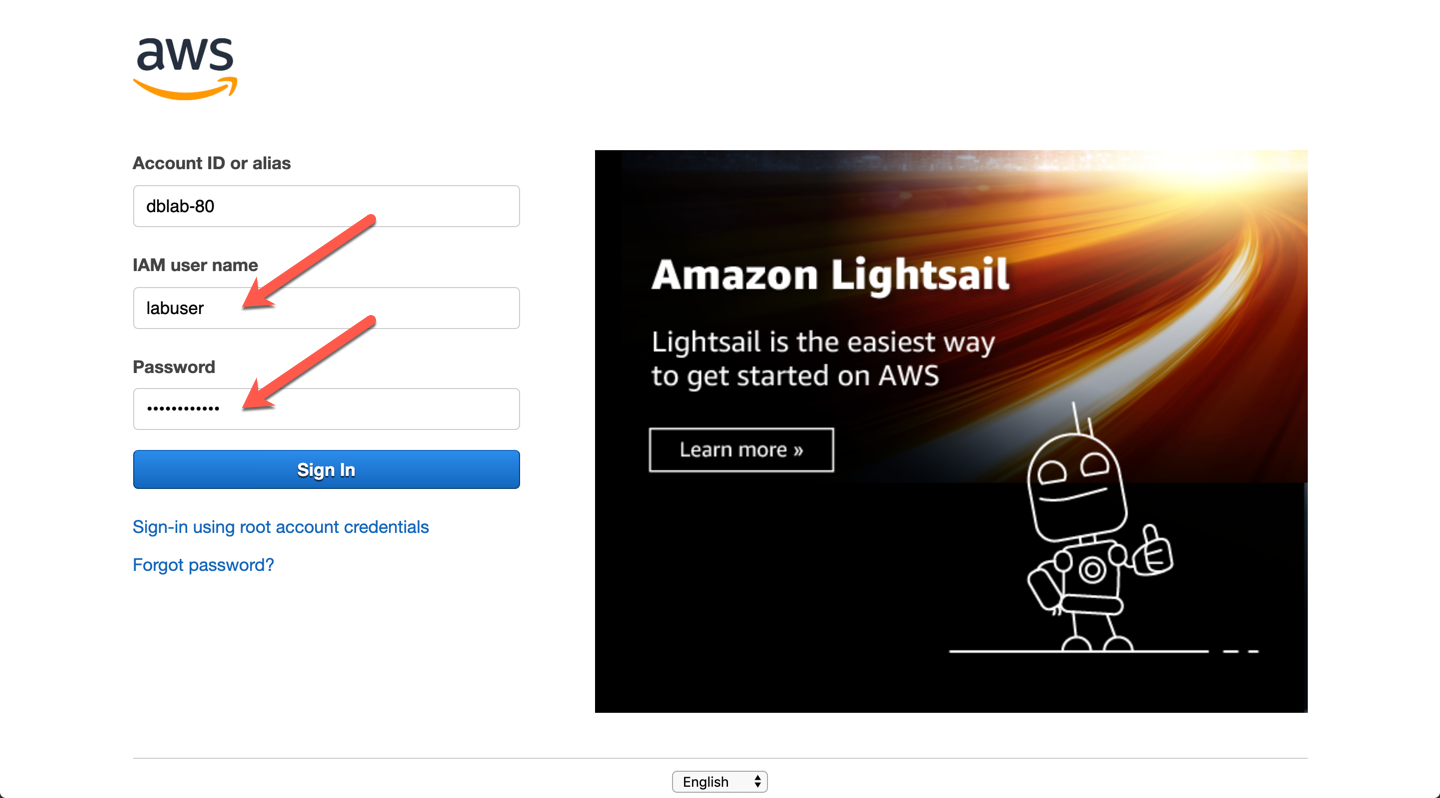
Acesse o AWS Management Console
Você pode acessar o console em : https://console.aws.amazon.com/ ou por meio do mecanismo de logon único (SSO) fornecido por sua organização.
Os laboratórios são projetados para funcionar em qualquer uma das regiões onde o Amazon Aurora MySQL compatível está disponível. No entanto, nem todos os recursos e capacidades do Amazon Aurora podem estar disponíveis em todas as regiões com suporte no momento.
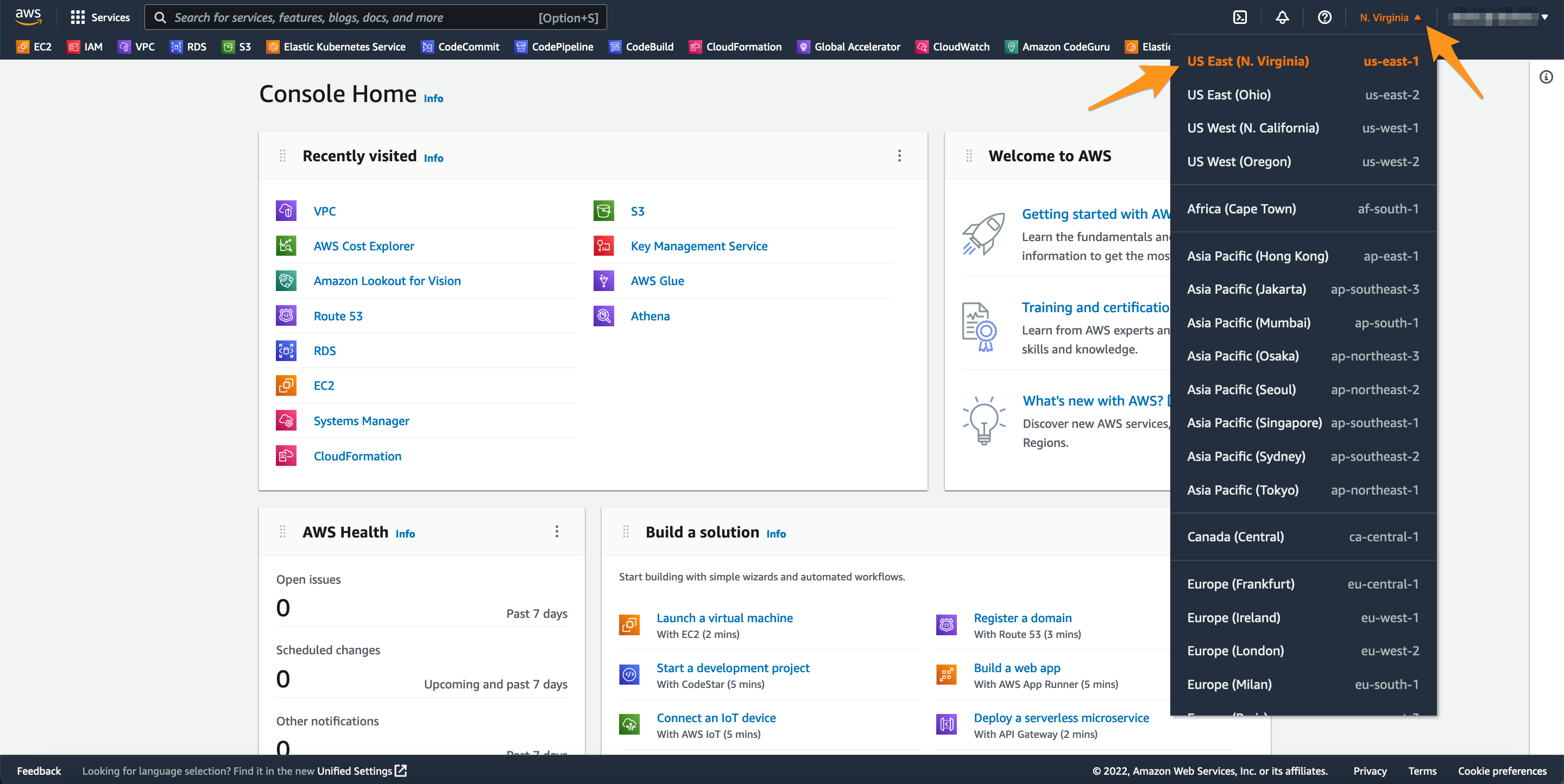
Essa lab utiliza a região US East (N. Virginia) / us-east-1 para a região secundária do Aurora Global Database, nesse caso recomendamos utilizar a região de Ohio / us-east-1 para o ambiente primario.
Criar o ambiente de laboratório usando AWS CloudFormation
Para simplificar a experiência inicial com os laboratórios, criamos modelos básicos para AWS CloudFormation que provisionam os recursos necessários para o ambiente de laboratório. Esses modelos são projetados para implantar uma infraestrutura de rede consistente e componentes usados no laboratório.
Clique em Launch Stack para criar um cluster de banco de dados provisionado Aurora automaticamente:

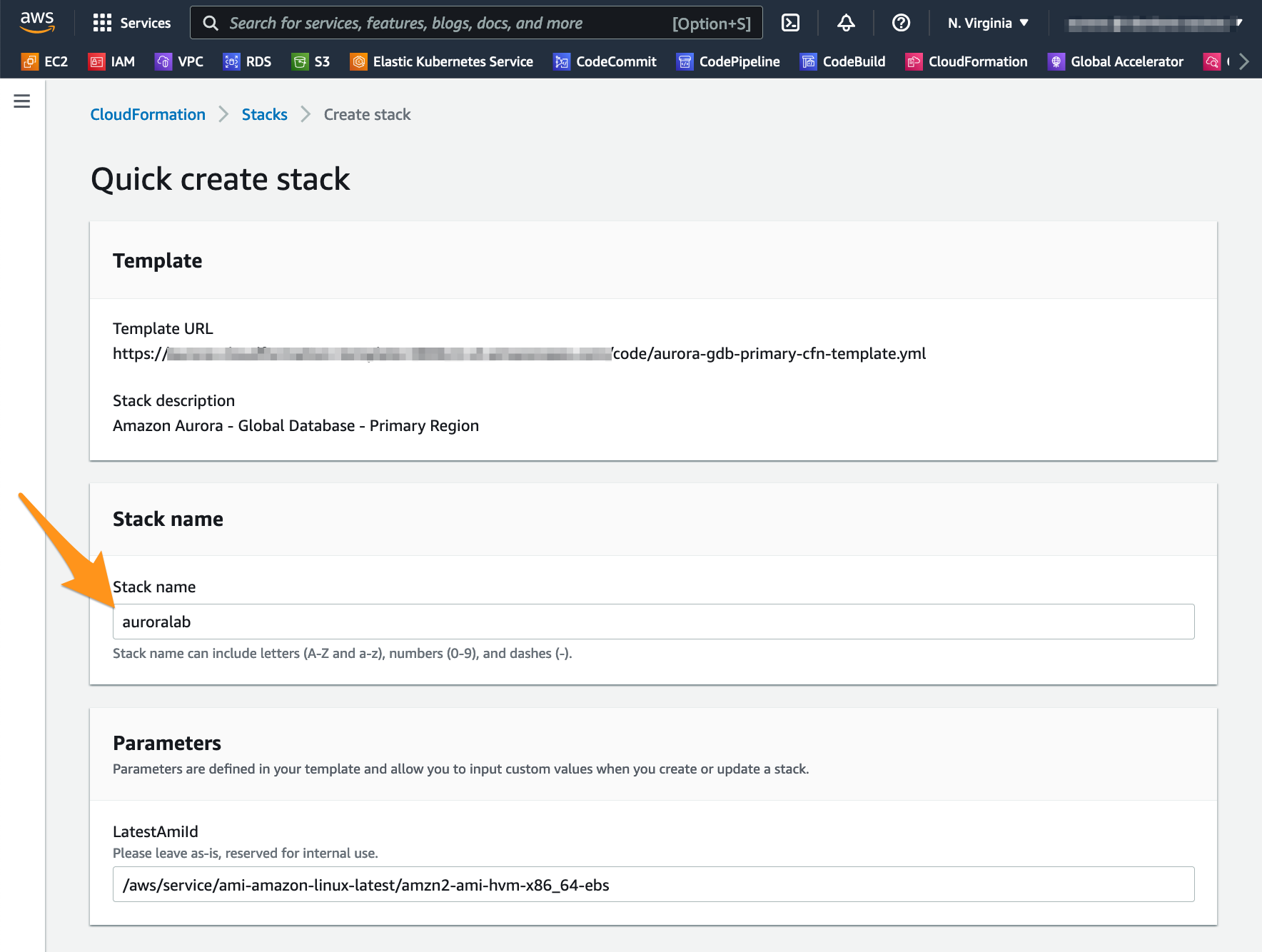
No campo denominado Stack Name, verifique se o valor auroralab está predefinido.
Para rodar o Lab de Aurora Global Database, selecione também Yes para o parâmetro Enable Aurora Global Database Labs?
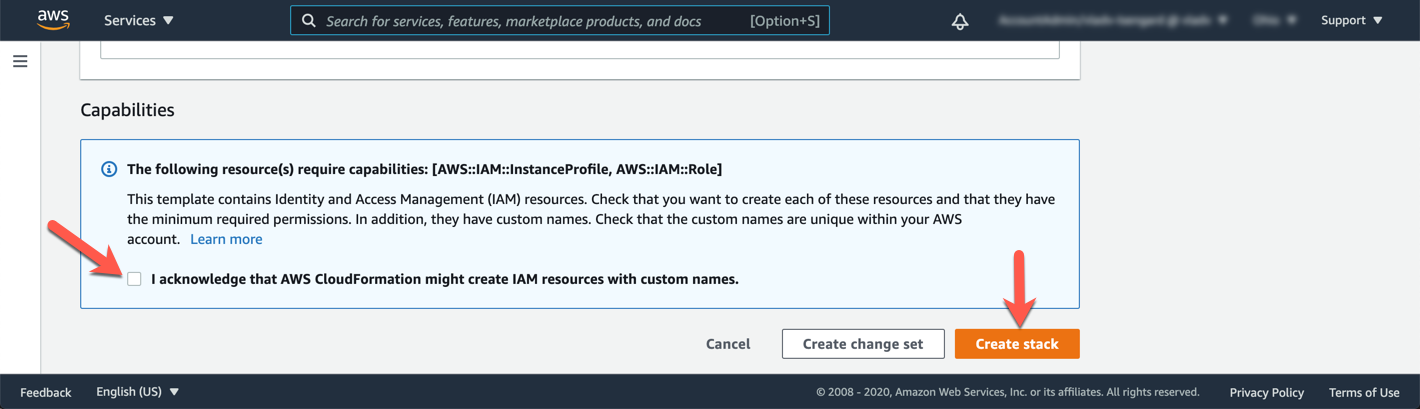
Vá até o final da página, marque a caixa que diz : I acknowledge that AWS CloudFormation might create IAM resources with custom names e clique em Create stack.
A stack levará aproximadamente 20 minutos para ser provisionada. Você pode monitorar o status na página Stack detail. Você pode monitorar o progresso do processo de criação da stack atualizando a guia Events. O último evento na lista indicará CREATE_COMPLETE para o recurso da stack.
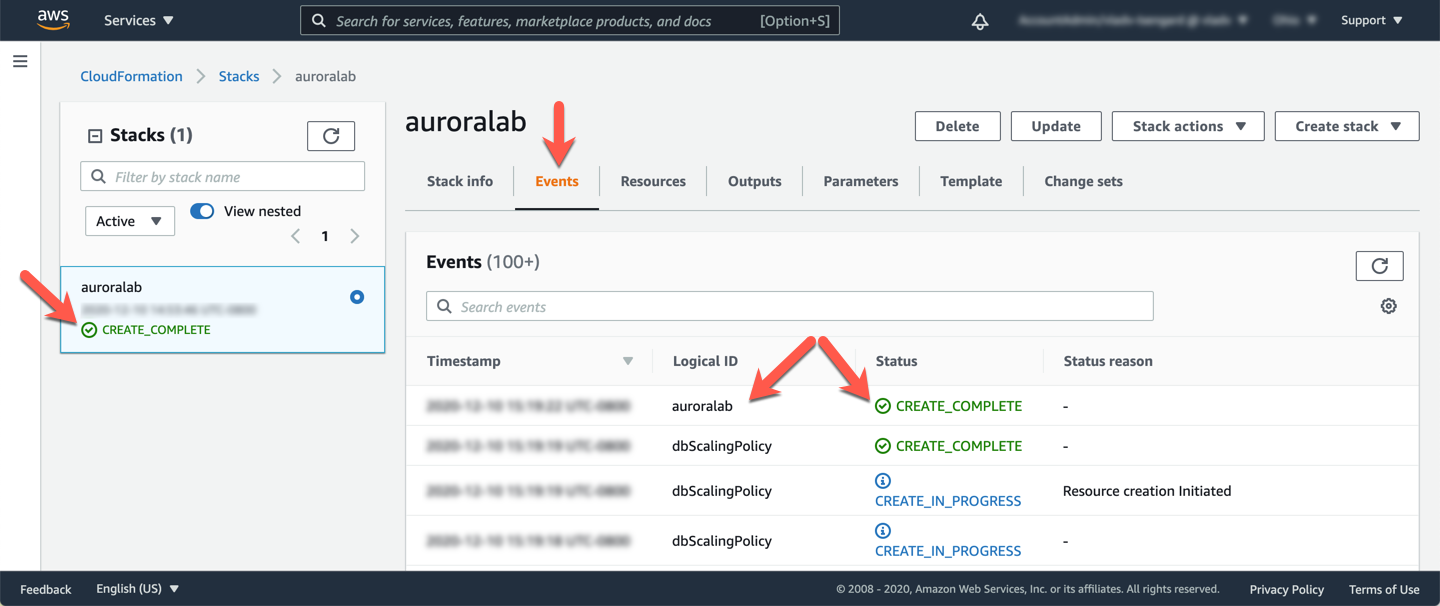
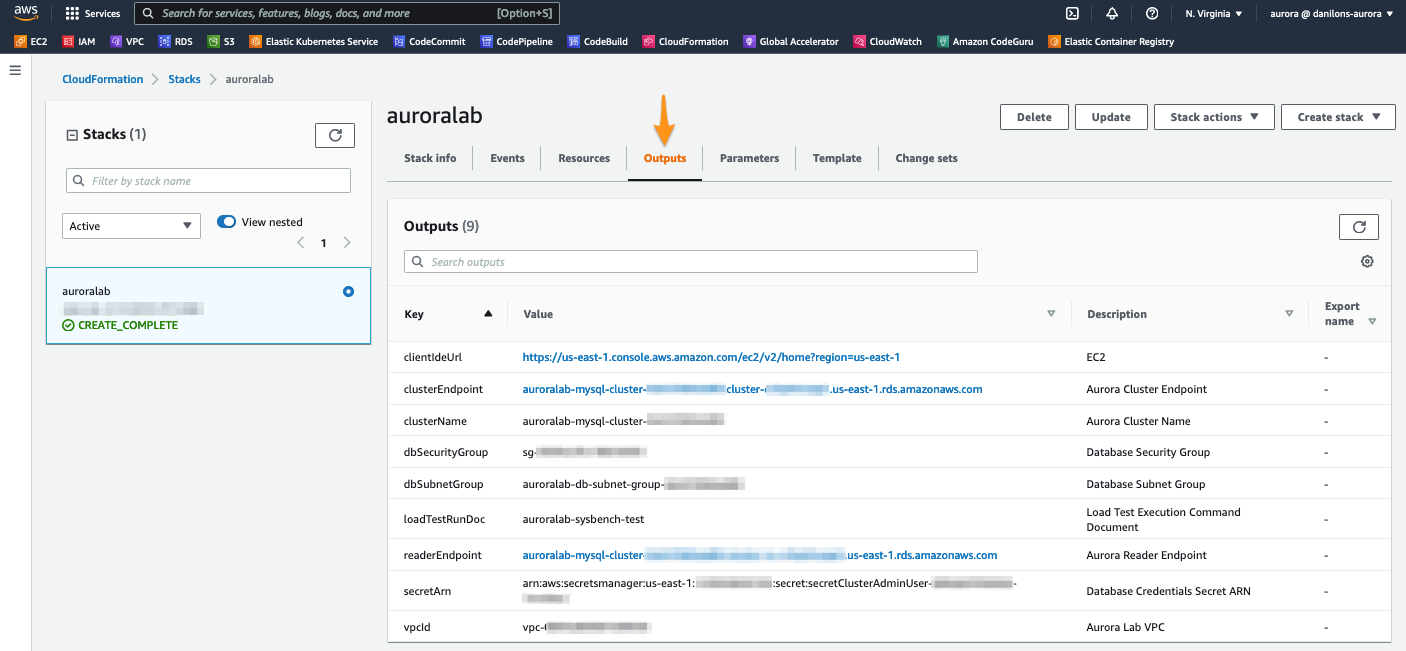
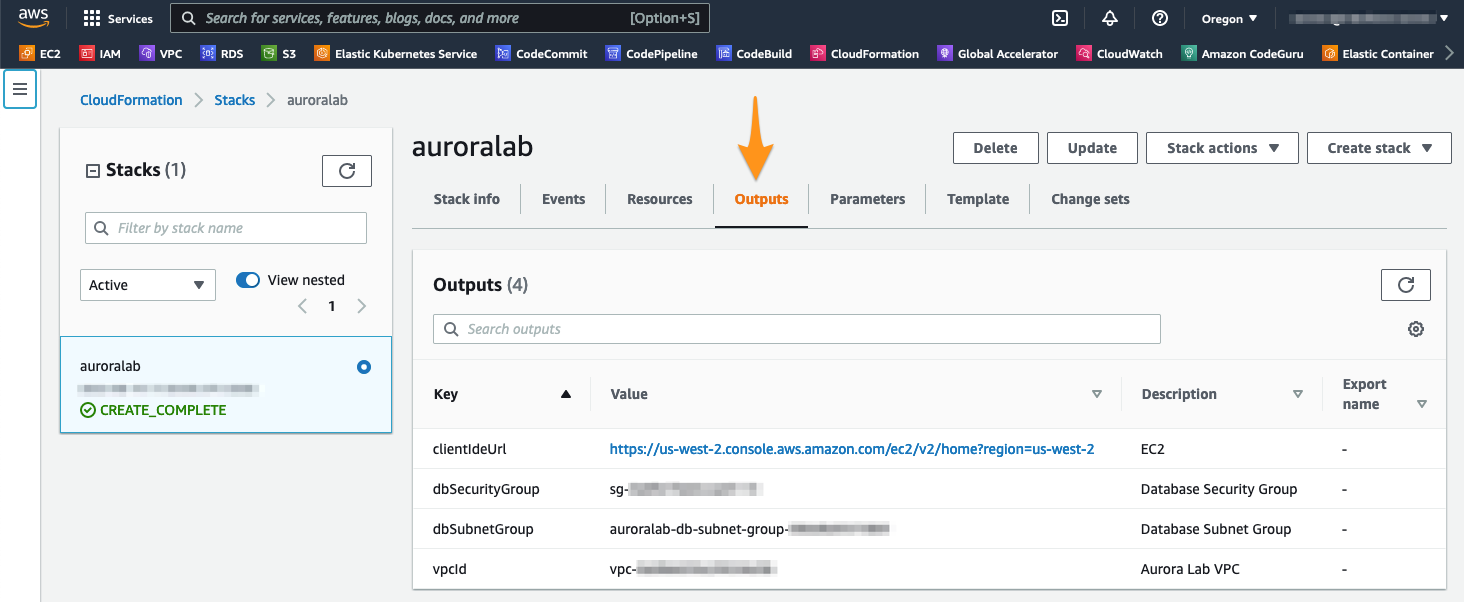
Quando o status da stack for CREATE_COMPLETE, clique na guia Outputs. Os valores aqui serão essenciais para a conclusão do restante do laboratório. Reserve um momento para salvar esses valores em um local onde tenha fácil acesso a eles durante o restante do laboratório. Os nomes que aparecem na coluna Key são referenciados diretamente nas instruções nas etapas subsequentes, usando o formato de parâmetro: ==[outputKey]==.
Agora vamos verificar o acesso ao Session Manager, de onde rodaremos alguns comandos nos laboratórios a seguir.
Não prossiga sem verificar o acesso ao Session Manager.
Crie um ambiente de laboratório na Região Virginia (us-east-1)
Usando multiplas regiões:
Devido à natureza multi-regional de um banco de dados global, você frequentemente alternará entre duas regiões para realizar as tarefas deste laboratório. Esteja ciente de que você está executando as ações na região adequada, pois alguns dos recursos criados são muito semelhantes entre as duas regiões. Vamos nos referir à região onde seu cluster de banco de dados atual está implantado, e você tem trabalhado até agora, como sua região primária. Vamos nos referir à região onde você implantará o cluster de banco de dados secundário e somente leitura como a região secundária.
Clique em Launch Stack abaixo para provisionar um ambiente de laboratório na região US East (N Virginia, us-east-1) para oferecer suporte ao Aurora Global Database.
No campo denominado Stack Name, verifique se o valor auroralab está predefinido. Aceite todos os valores padrão para os parâmetros restantes.
Vá até a parte inferior da página, marque a caixa que diz: I acknowledge that AWS CloudFormation might create IAM resources with custom names e clique em Create stack.
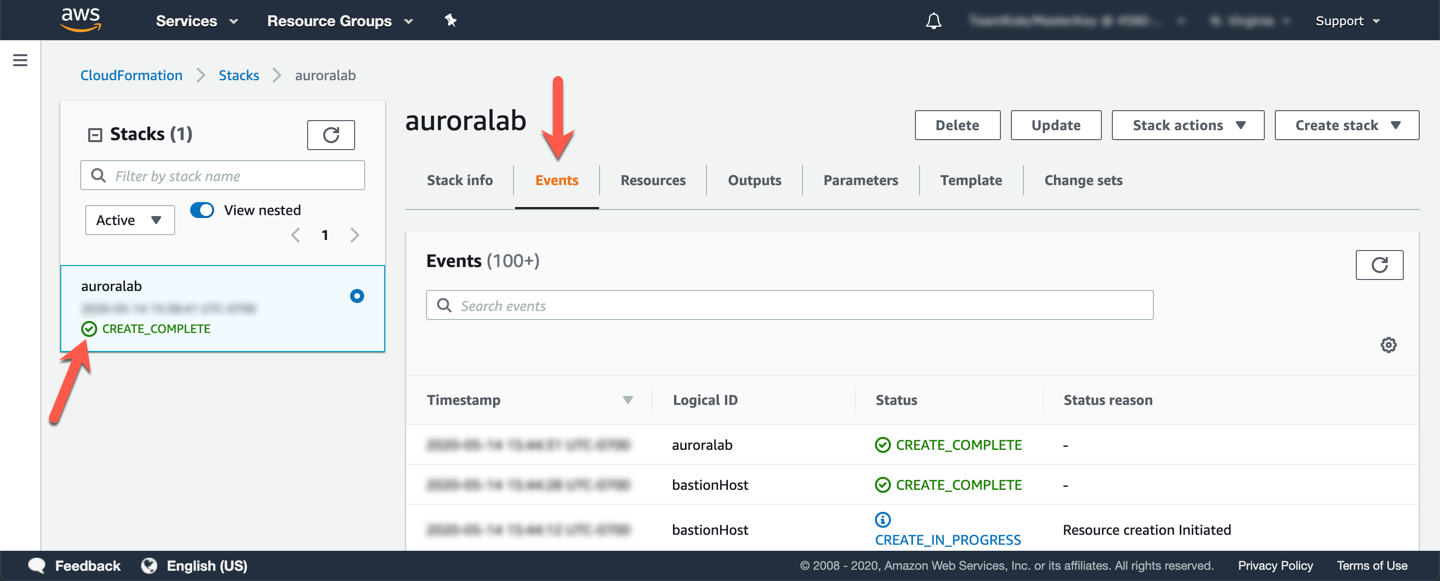
A stack levará aproximadamente 10 minutos para ser provisionada, você pode monitorar o status na página Stack detail. Você pode monitorar o progresso do processo de criação da pilha atualizando a guia Events. O último evento na lista indicará CREATE_COMPLETE para o recurso da stack.
Quando o status da stack for CREATE_COMPLETE, clique na guia Outputs. Os valores aqui serão essenciais para a conclusão do restante do laboratório. Reserve um momento para salvar esses valores em um local onde tenha fácil acesso a eles durante o restante do laboratório. Os nomes que aparecem na coluna Key são referenciados diretamente nas instruções nas etapas subsequentes, usando o formato de parâmetro: ==[outputKey]==.
3. Crie um Aurora global cluster
O ambiente de laboratório que foi provisionado automaticamente para você já tem um cluster Aurora MySQL DB, no qual você está executando o gerador de carga. Você criará um cluster de banco de dados global usando este cluster de banco de dados existente, como o primária.
‘Global cluster’ vs. ‘DB cluster’: Qual é a diferença?
Um DB Cluster existe em apenas uma região. É um contêiner para até 16 instâncias de banco de dados que compartilham o mesmo volume de armazenamento. Esta é a configuração tradicional de um cluster Aurora. Esteja você implantando um cluster provisionado, serverless ou multi-master, você está implantando um cluster DB em uma única região.
Um cluster global é um contêiner para vários clusters de banco de dados, cada um localizado em uma região diferente, que atuam como um banco de dados coeso. Um cluster global é composto por um cluster [DB] primário em uma determinada região que é capaz de aceitar gravações e até 5 clusters [DB] secundários que são somente leitura, cada em uma região diferente. Cada um dos clusters de banco de dados em um determinado cluster global tem seu próprio volume de armazenamento, mas os dados são replicados do cluster primário para cada um dos clusters secundários de forma assíncrona, usando um sistema de replicação de baixa latência e alto rendimento desenvolvido para esse fim.
Uma vez que o ambiente de laboratório criado no passo 1. Crie um ambiente de laboratório na Região Ohio (us-east-2) esteja finalizado, podemos continuar.
Abra o Amazon RDS service console na página de detalhes do cluster MySQL DB na região primária. Se você navegou para o console RDS por outro meio que não o link neste parágrafo, clique em auroralab-mysql-cluster na seção Databases do console de serviço RDS, e certifique-se de estar de volta a região primária.
Verifique se você ainda está trabalhando na região primária, especialmente se estiver seguindo os links acima para abrir o console de serviço na tela certa.
Primeiro, você precisa desativar o recurso Backtrack. No momento, o backtrack do banco de dados não é compatível com os bancos de dados globais do Aurora, e um cluster com esse recurso ativo não pode ser convertido em um banco de dados global. Selecione o auroralab-mysql-cluster e clique no botão Modify.
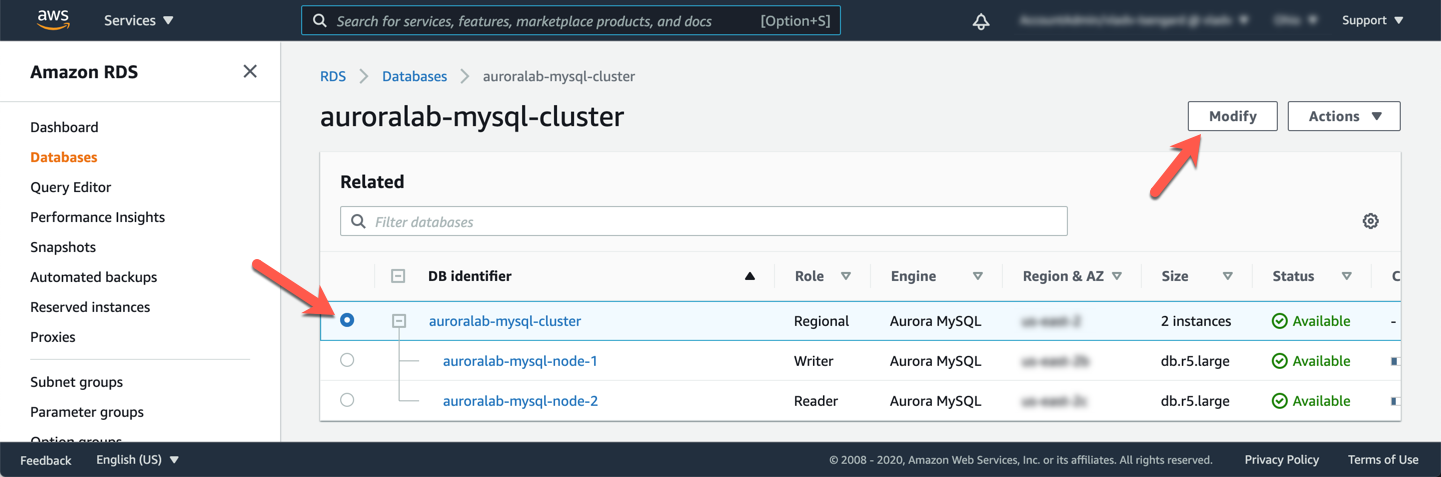
Vá até a seção Additional Configuration (expanda-a se necessário) e desmarque a opção Enable Backtrack, então clique em Continue na parte inferior da página.
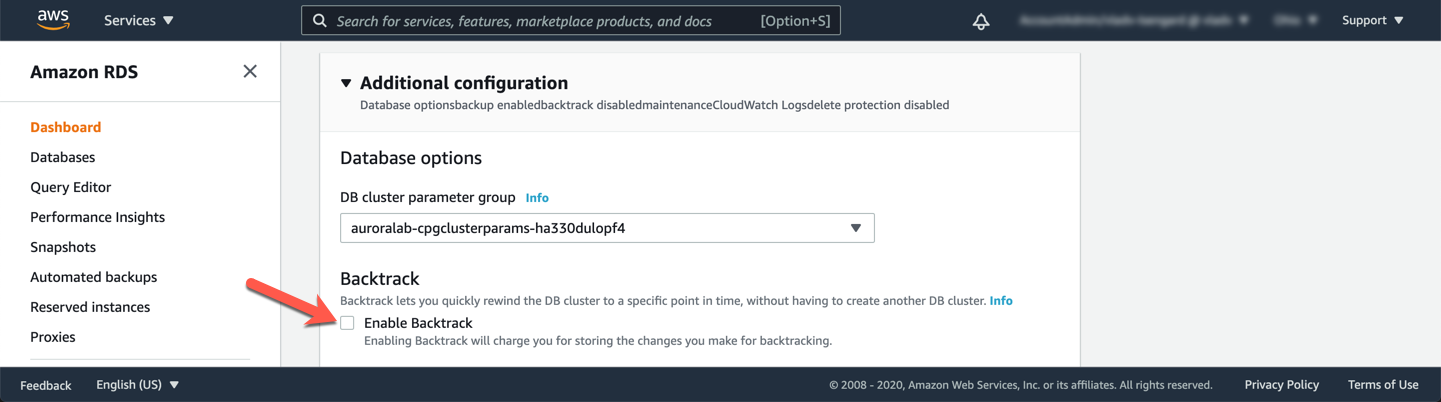
Na seção Scheduling of modifications, escolha a opção Apply immediately e clique em Modify cluster para confirmar as alterações.
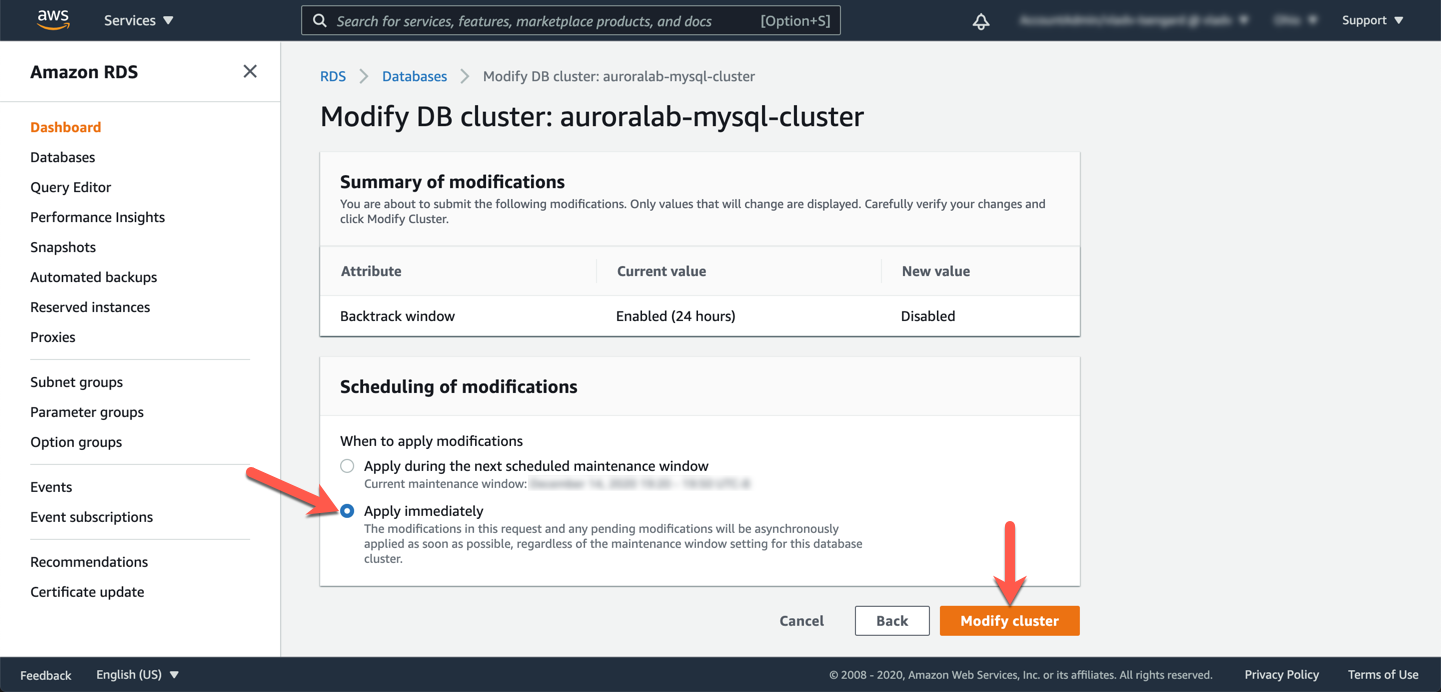
Quando a modificação for concluída, e o cluster de banco de dados estiver em um estado available novamente, no botão suspenso Actions, escolha Add region..
Pode ser necessário atualizar a página do navegador após desativar o Backtrack, antes de adicionar uma região. Se Add region aparecer indisponivel, atualize a página do navegador ou verifique se Backtrack foi desativado corretamente.
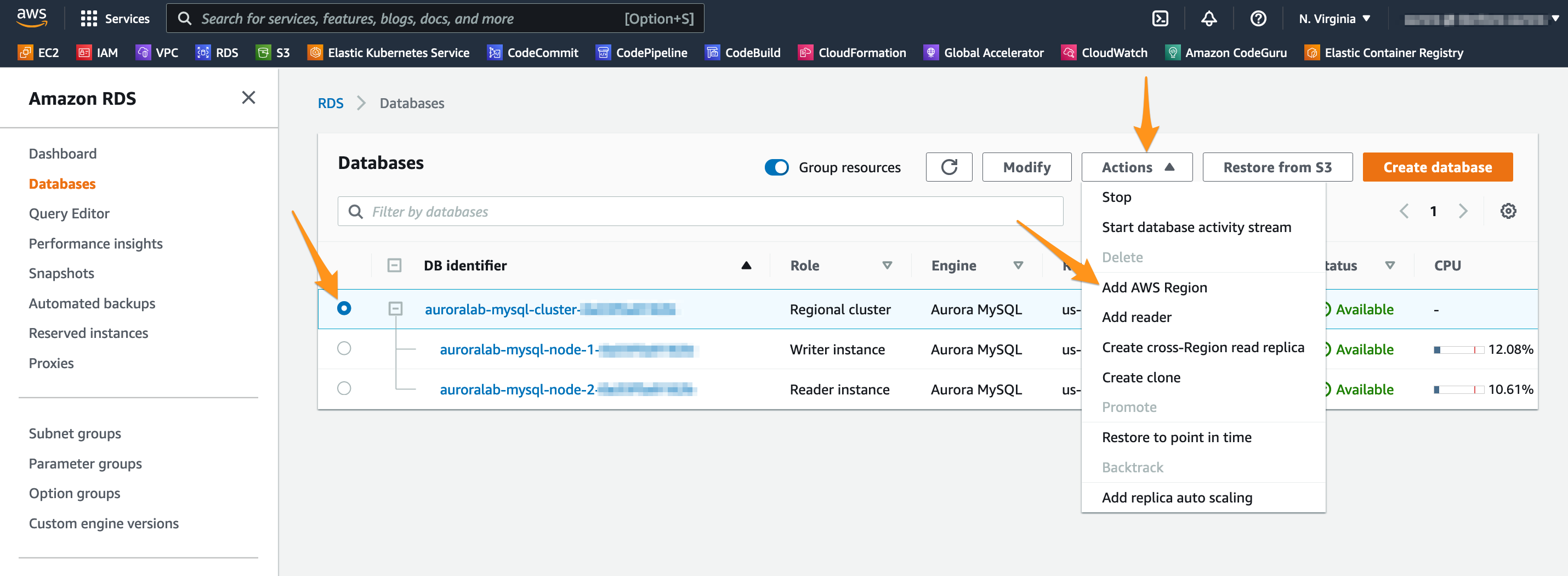
Defina as seguintes opções na tela de configuração para o cluster de banco de dados secundário:
-
Na seção Global database settings:
- Em Global database identifier coloque
auroralab-mysql-global
- Em Global database identifier coloque
-
Na seção AWS Region:
- Escolha a região secundária de
US East (N. Virginia)
- Escolha a região secundária de
-
Em Connectivity, especifique onde o cluster de banco de dados será implantado com as informações de rede criadas acima:
- Em Virtual Private Cloud (VPC) coloque
auroralab-vpc - Garanta que o correto Subnet Group foi selecionado automaticamente, deve ter o nome
auroralab-db-subnet-group. - Certifique-se de que a opção Publicly accessible está definida como
No - Para VPC security group selecione Choose existing e escolha o grupo de segurança chamado
auroralab-database-sg, remova quaisquer outros grupos de segurança, comodefaultda seleção.
- Em Virtual Private Cloud (VPC) coloque
-
Em Read replica write forwarding:
- Marque a opção Enable read replica write forwarding
-
Expanda a seção Advanced configuration, e configure as seguintes opções:
- Para DB instance identifier escolha
auroralab-mysql-node-3 - Para DB cluster identifier escolha
auroralab-mysql-secondary - Para DB cluster parameter group selecione o grupo com o nome da stack no nome (ex.
auroralab-[...]) - Para DB parameter group selecione o grupo com o nome da stack no nome (ex.
auroralab-[...]) - Para Backup retention period escolha
1 day - Marque a opção Enable Performance Insights
- Para Retention period escolha
Default (7 days) - Para Master key escolha
[default] aws/rds - Marque a opção Enable Enhanced Monitoring
- Para Granularity escolha
1 second - Para Monitoring Role escolha
auroralab-monitor-[secondary-region]
- Para DB instance identifier escolha
Observe que há duas funções de monitoramento na lista, uma para a região primária (uma no canto superior direito), a outra para a região secundária (normalmente us-east-1) . Nesta etapa, você precisa da região secundária.
O que essas opções significam?
Você criará um cluster global, um cluster de banco de dados secundário e uma instância de banco de dados nesse cluster secundário, em uma única etapa. Seu cluster de banco de dados existente se tornará o cluster de banco de dados principal no novo cluster global. Estas são chamadas API distintas para o serviço RDS, caso você crie um cluster global usando o AWS CLI, SDKs ou outras ferramentas. O console de serviço RDS simplesmente combina essas etapas distintas em uma única operação.
Clique em Add region para criar o global cluster.
A criação de um cluster global com base no cluster de banco de dados existente é uma operação trânsparente, o cluster atual não sofrerá nenhuma interrupção. Você pode monitorar as métricas de desempenho ao longo desta operação.
O cluster global, incluindo o cluster de banco de dados secundário, pode levar até 30 minutos para ser provisionado.
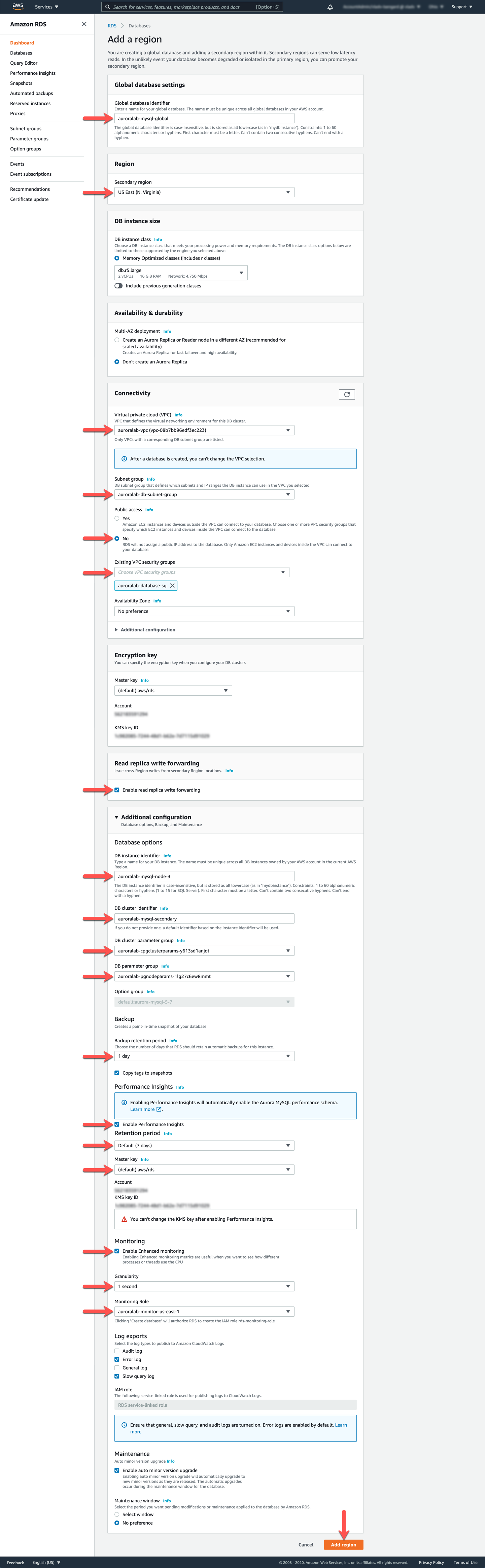
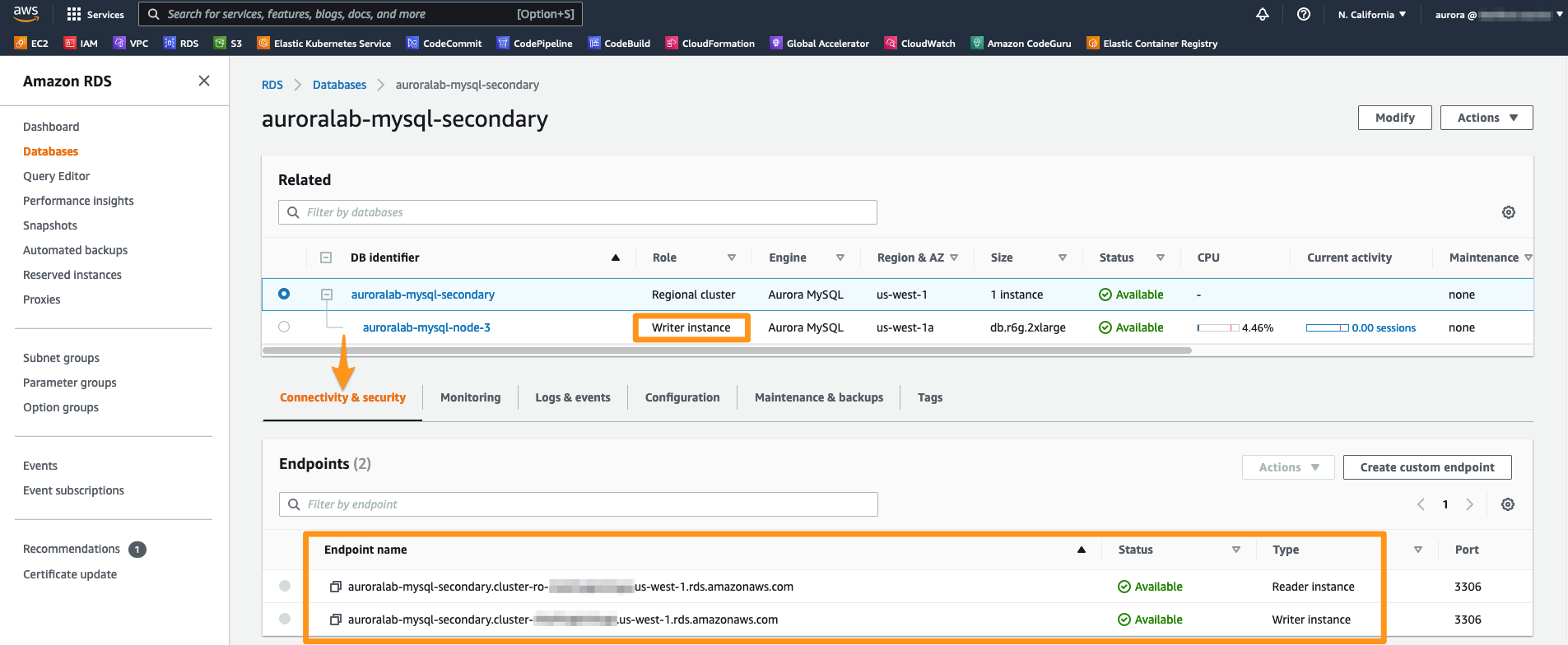
Para se conectar ao cluster de banco de dados e começar a usá-lo, é necessário recuperar os endereços de acesso do cluster de banco de dados. Ao contrário de um cluster de banco de dados regular, apenas o Reader Endpoint é provisionado. O Cluster Endpoint não é criado, pois os clusters de banco de dados secundários contêm apenas leitores e não podem aceitar gravações. O Reader Endpoint sempre resolverá para uma das instâncias do banco de dados e deve ser usado para operações de leitura de baixa latência nessa região. No console RDS, vá para a visualização de detalhes do cluster de banco de dados clicando no cluster detail para o cluster de banco de dados secundário, denominado auroralab-mysql-secondary.
A seção Endpoints na guia Connectivity and security da página de detalhes exibe os endpoints.
Monitore o Global Database
O Amazon Aurora expõe uma variedade de métricas do Amazon CloudWatch , que você pode usar para monitorar e determinar a integridade e o desempenho de seu banco de dados global Aurora. Neste laboratório, você criará um dashboard Amazon CloudWatch para monitorar a latência, o IO replicado e a transferência de dados de replicação entre regiões para nosso banco de dados global Aurora.
Este laboratório contém as seguintes tarefas:
- Gerar carga no cluster de banco de dados primário
- Monitore a carga do cluster e o atraso de replicação
Este laboratório requer os seguintes pré-requisitos:
1. Gerar carga no cluster de banco de dados primário
Você usará o script de benchmark semelhante ao TPCC da Percona com base no sysbench para gerar a carga. Para simplificar, empacotamos o conjunto correto de comandos em um Documento de comando do AWS Systems Manager . Você usará o AWS Systems Manager Run Command para executar o teste.
Se você ainda não estiver conectado ao terminal do Session Manager, conecte-se seguindo estas instruções na região primária. Uma vez conectado, digite os comandos a seguir, substituindo os marcadores de posição apropriadamente.
Verifique se você ainda está trabalhando na região primária
aws ssm send-command \
--document-name [loadTestRunDoc] \
--instance-ids [ec2Instance]
Não esqueça de verificar se o Session Manager está aberto na região primária.
- O valor para [loadTestRunDoc] está definido no output da Stack do CloudFormation utilizada para criar o ambiente primário. Normalmente o valor será auroralab-sysbench-test.
- O [ec2Instance] é o ID da instance do workspace, e pode ser encontrado na parte superior da tela do Session Manager. Ou no output da Stack do CloudFormation.
O que todos esses parâmetros significam? Parameter | Description — | — –document-name | O nome do documento de comando a ser executado. –instance-ids | A instância EC2 para executar este comando.
O comando será enviado para a instância EC2 que preparará o conjunto de dados de teste e executará o teste de carga. Pode levar até um minuto para que o CloudWatch reflita a carga adicional nas métricas. Você verá uma confirmação de que o comando foi iniciado.
2. Monitore a carga do cluster e o atraso de replicação
No console de serviço RDS na região primária, selecione auroralab-mysql-cluster (primário), se ainda não estiver selecionado e alterne para a guia Monitoring. Você verá uma visão combinada das instâncias de banco de dados de escrita e leitura nesse cluster. Você não está usando os nós de leitura neste momento, a carga é direcionada apenas para o nó de escrita. Navegue pelas métricas e analise especificamente as métricas CPU Utilization, Commit Throughput, DML Throughput, Select Throughput e observe que estão razoavelmente estáveis, além do pico inicial causado pela ferramenta sysbench preenchendo um conjunto de dados inicial.
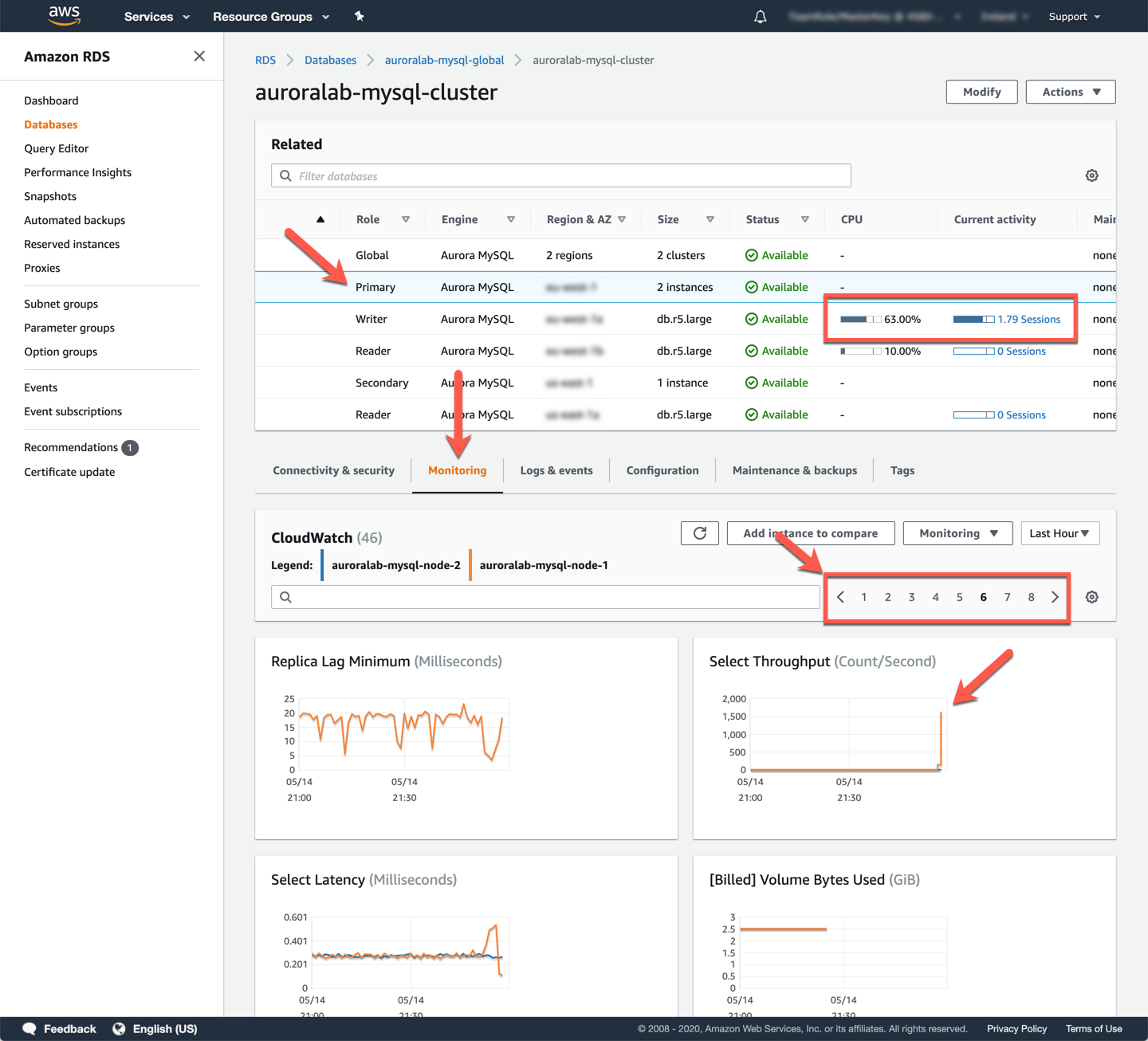
Em seguida, você mudará o foco para o cluster de banco de dados secundário recém-criado. Você criará um painel do CloudWatch para monitorar três métricas principais relevantes para clusters globais e clusters de banco de dados secundários, mais especificamente:
| CloudWatch Metric Name | Descrição |
|---|---|
AuroraGlobalDBReplicatedWriteIO |
O número de Write IO replicado para a região secundária |
AuroraGlobalDBDataTransferBytes |
A quantidade de redo logs transferidos para a região secundária, em bytes |
AuroraGlobalDBReplicationLag |
O quão atrás, medido em milissegundos, a região secundária fica atrás do cluster na região primária |
Abre o console do Amazon CloudWatch na região secundária (us-east-1), no menu Dashboards.
Você trabalhará em uma região diferente nas etapas subsequentes: N. Virginia (us-east-1). Como você pode ter várias guias do navegador e sessões de linha de comando abertas, certifique-se de estar sempre operando na região pretendida.
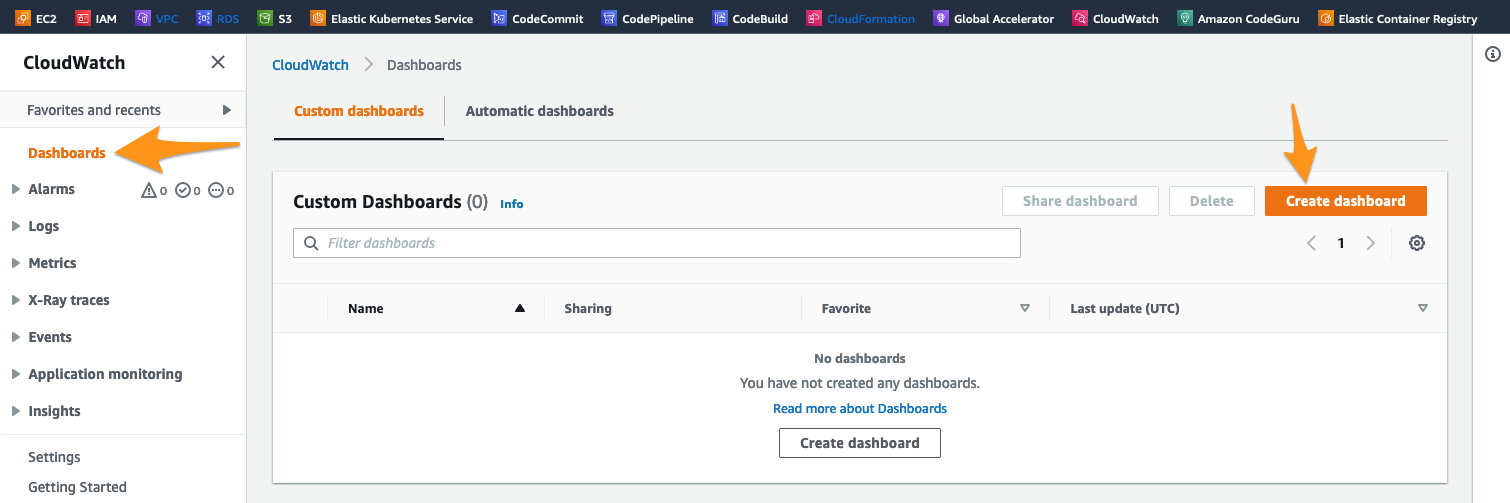
Clique em Create dashboard. Defina o nome da nova dashboard auroralab-gdb-dashboard e clique em Create dashboard.
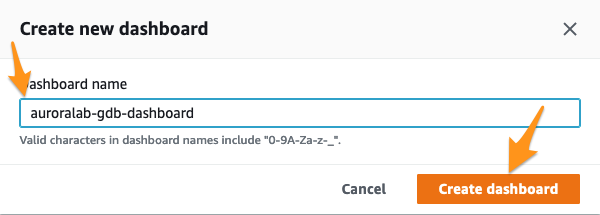
Vamos adicionar nosso primeiro widget no painel que mostrará nossa latência de replicação entre o cluster Aurora secundário e primário. Selecione Number e clique em Next.
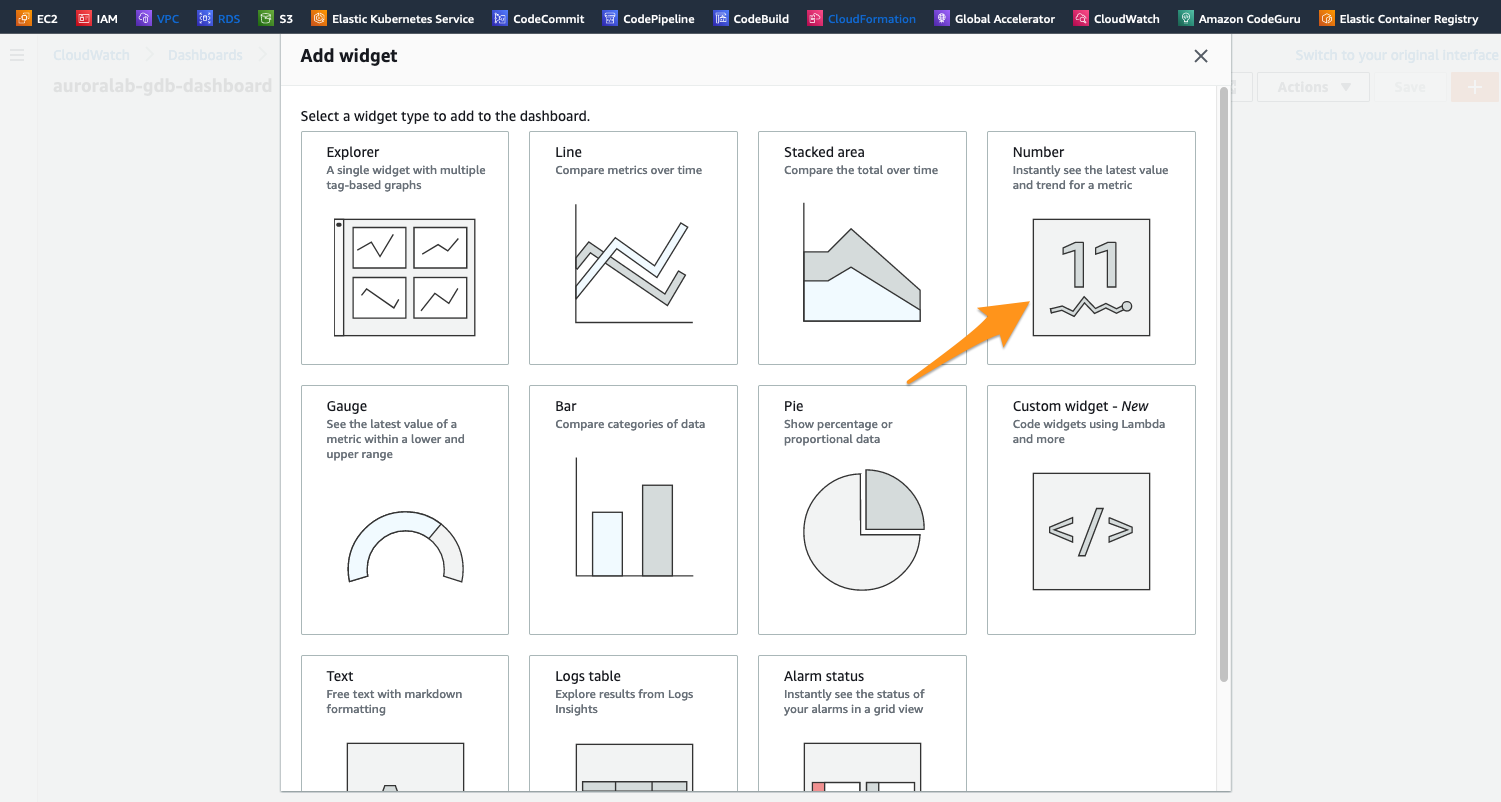
Na tela de Add Metric Graph, examinaremos a guia All Metrics, selecionaremos RDS e, em seguida, selecionaremos o grupo de métricas denominado SourceRegion.
Agora você deve ver uma métrica filtrado AuroraGlobalDBReplicationLag, com a coluna SourceRegion como o nome de sua região primária do cluster global. Selecione esta métrica usando a caixa de seleção.
A visualização do widget agora deve estar no topo com uma amostra do tempo de atraso em milissegundos. Vamos atualizar ainda mais o widget. Dê a ele um nome amigável clicando no ícone de edição (ícone de lápis) e renomeie o widget de Untitled Graph paraGlobal DB Replication Lag (avg, 1min), pressione o ícone de marcação para enviar suas alterações.
Na parte inferior, clique na guia Graphed Metrics para personalizar ainda mais nossa visualização. Na coluna Statistic, altere para Average e Period para 1 minuto.
Confirme se as configurações estão iguais ao exemplo abaixo, e clique em Create widget.
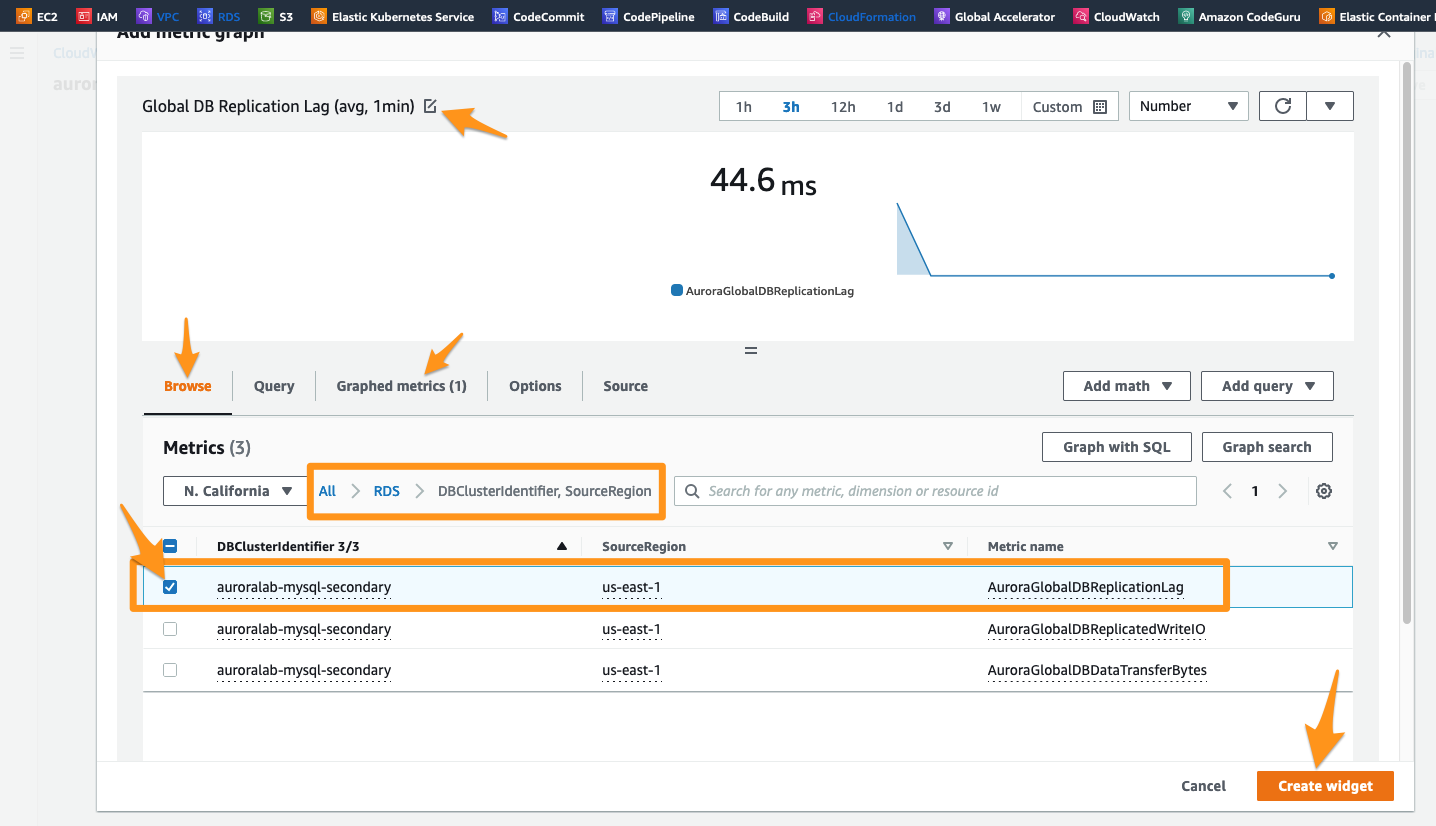
Agora você criou seu primeiro widget. Você pode definir uma atualização automática em um intervalo definido no menu de atualização no canto superior direito.
Clique em Save dashboard para salvar as alterações.
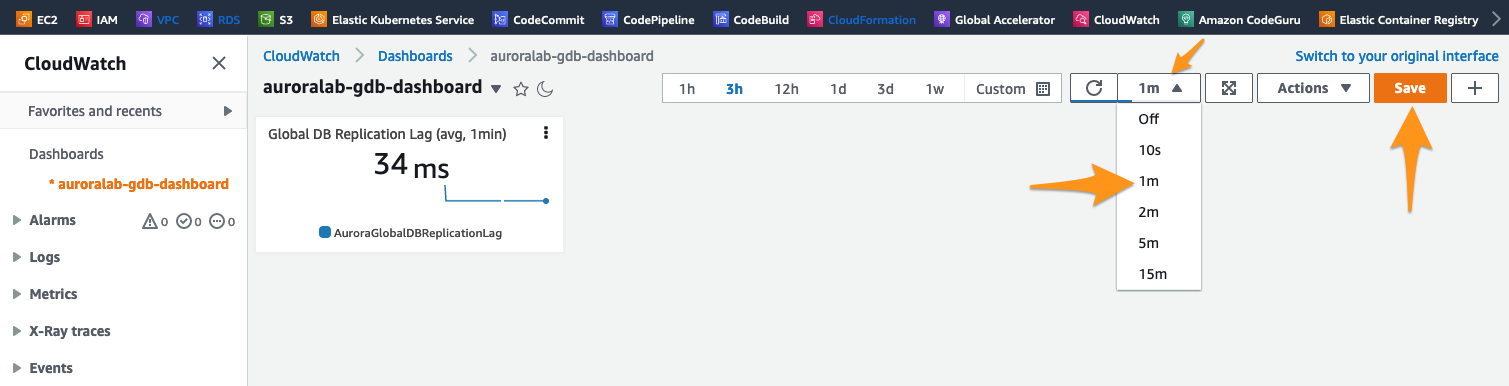
Você pode adicionar widgets individualmente ao dashboard, para construir um painel de monitoramento mais completo. No entanto, para economizar tempo, vamos utilziar o JSON abaixo.
Primeiro, clique na lista suspensa Actions no painel e escolha View/edit source.
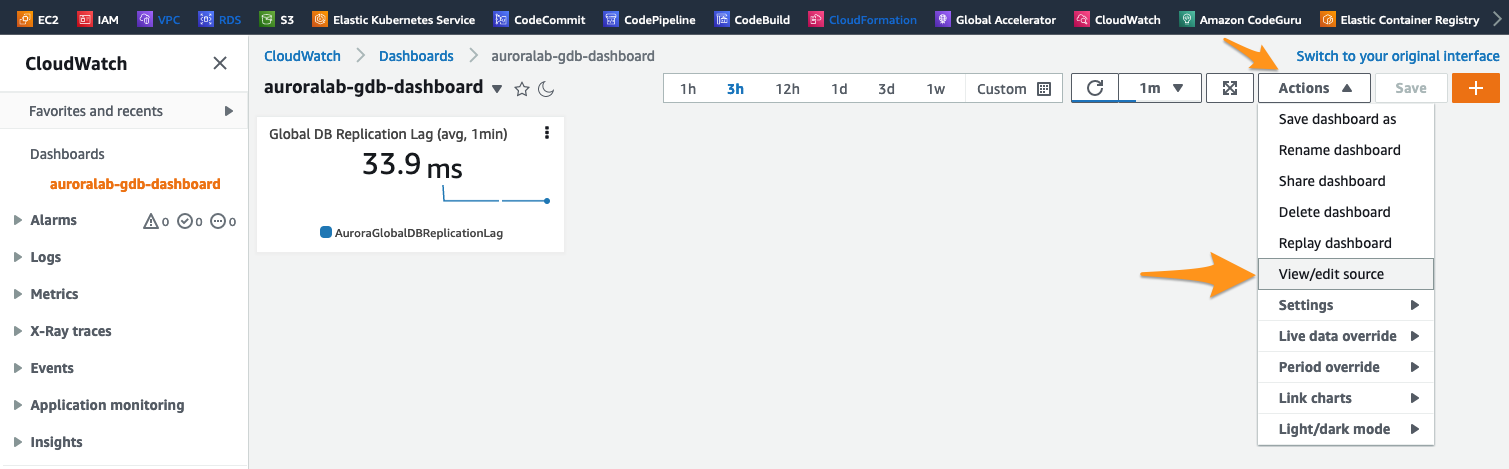
Na caixa de texto que aparece na tela, cole o seguinte código JSON. Certifique-se de atualizar a região AWS no código abaixo para corresponder à sua região secundária,se necessário. Além disso, se você usou identificadores (nomes) de cluster de BD diferentes para os clusters de BD do que os indicados neste guia, você também terá que atualizá-los.
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 3,
"width": 24,
"height": 6,
"properties": {
"metrics": [
[ "AWS/RDS", "AuroraGlobalDBReplicationLag", "DBClusterIdentifier", "auroralab-mysql-secondary" ],
[ "...", { "stat": "Maximum" } ]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "Global DB Replication Lag (max vs. avg, 1min)",
"stat": "Average",
"period": 60
}
},
{
"type": "metric",
"x": 0,
"y": 0,
"width": 9,
"height": 3,
"properties": {
"metrics": [
[ "AWS/RDS", "AuroraGlobalDBReplicationLag", "DBClusterIdentifier", "auroralab-mysql-secondary" ]
],
"view": "singleValue",
"region": "us-east-1",
"title": "Global DB Replication Lag (avg, 1min)",
"stat": "Average",
"period": 60
}
},
{
"type": "metric",
"x": 9,
"y": 0,
"width": 15,
"height": 3,
"properties": {
"metrics": [
[ "AWS/RDS", "AuroraGlobalDBReplicatedWriteIO", "DBClusterIdentifier", "auroralab-mysql-secondary", { "label": "Global DB Replicated Write IOs" } ],
[ ".", "AuroraGlobalDBDataTransferBytes", ".", ".", { "label": "Global DB DataTransfer Bytes" } ]
],
"view": "singleValue",
"region": "us-east-1",
"stat": "Sum",
"period": 86400,
"title": "Billable Replication Metrics (aggregate, last 24 hr)"
}
}
]
}
Clique em Update para alterar o dashboard.
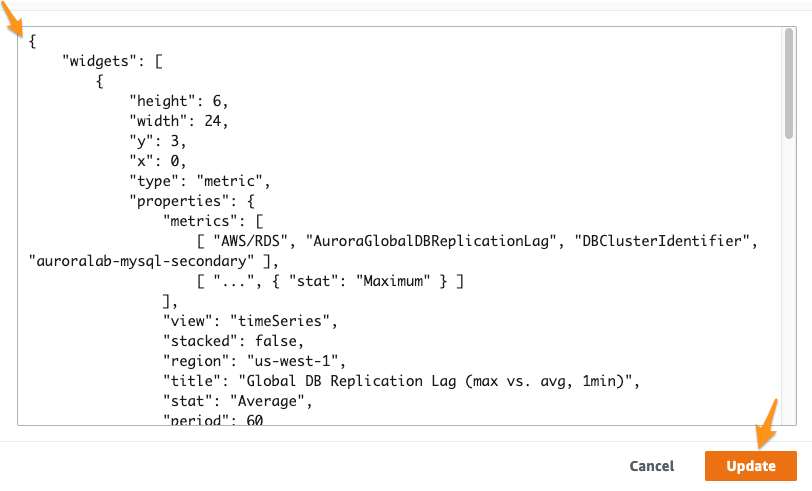
Clique em Save dashboard para garantir que o painel seja salvo com as novas alterações .
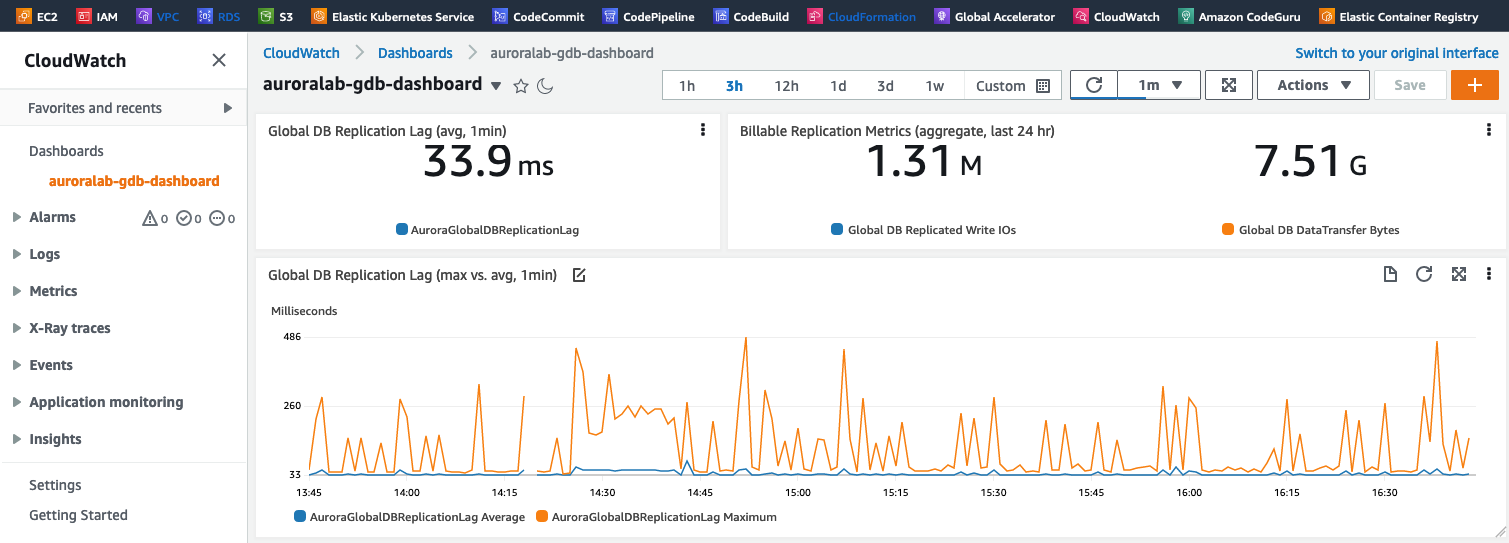
As métricas Aurora Global DB Replicated I/O e Aurora Global DB Data Transfer Bytes são atualizadas apenas uma vez por hora, portanto, talvez você não consiga ver os dados dessas métricas, dependendo do tempo de seu laboratório.
Fail Over no Aurora Global Database
Quando usado em combinação com réplicas na região, um cluster Aurora DB fornece recursos de failover automático dentro da região. Com o Aurora Global Database, você pode executar um failover manual para o cluster de banco de dados em sua região secundária, de forma que seu banco de dados possa sobreviver no cenário improvável de uma infraestrutura ou serviço de uma região inteira ficar indisponível.
Combinado com uma camada de aplicação implementada em várias regiões (via infraestrutura imutável ou ( copiando suas AMIs entre regiões ), você pode aumentar ainda mais a disponibilidade de suas aplicações enquanto mantém a consistência dos dados.
Este laboratório contém as seguintes tarefas:
- Injete uma falha na região primária
- Promova o cluster de banco de dados secundário
Este laboratório requer os seguintes pré-requisitos:
- Conecte-se à estação de trabalho do Session Manager
- Cluster Aurora Global Database criado e em funcionamento
1. Injete uma falha na região primária
Se você ainda não estiver conectado à linha de comando da estação de trabalho do Session Manager, conecte-se seguindo estas instruções na região primária. Uma vez conectado, digite um dos seguintes comandos, substituindo os marcadores de posição apropriadamente.
Como você pode ter várias guias do navegador abertas, certifique-se de estar sempre operando na região pretendida.
mysql -h[clusterEndpoint] -u$DBUSER -p"$DBPASS" mylab
Onde encontro o endpoint do cluster (ou qualquer outro parâmetro)?
Como você está trabalhando com um banco de dados global Aurora, existem vários endpoints, nas regiões primárias e secundárias, que você terá que manter o controle. Verifique o final do laboratório [Implantar um banco de dados global] para obter instruções sobre como encontrar os endereços de conexão do cluster.
Uma vez conectado ao banco de dados, use o código abaixo para criar uma tabela. Execute as seguintes consultas SQL:
DROP TABLE IF EXISTS failovertest1;
CREATE TABLE failovertest1 (
pk INT NOT NULL AUTO_INCREMENT,
gen_number INT NOT NULL,
some_text VARCHAR(100),
input_dt DATETIME,
PRIMARY KEY (pk)
);
INSERT INTO failovertest1 (gen_number, some_text, input_dt)
VALUES (100,"region-1-input",now());
COMMIT;
SELECT * FROM failovertest1;
Anote os resultados da consulta, você os usará mais tarde para comparar.
Você pode simular uma falha na região usando vários mecanismos. No entanto, neste caso, você simulará uma falha de longo prazo e em maior escala (embora infrequente), e a melhor maneira de fazer isso é interromper todo o tráfego de entrada/saída de dados dentro e fora do cluster de banco de dados principal do Aurora Global Database. Seu ambiente de laboratório contém uma Rede VPC ACL (NACL) com uma regra DENY ALL específica, que bloqueará todo o tráfego de entrada/saída das sub-redes associadas. Isso basicamente emulará uma falha mais ampla que tornará o cluster de banco de dados da região primária indisponível para seus aplicativos.
Abra o console de serviço VPC na região primária na seção Network ACLs. Você deve ver um NACL chamado auroralab-denyall-nacl e que não está atualmente associado a nenhuma sub-rede. Selecione-o marcando a caixa ao lado do nome e revise as guias Inbound Rules e Outbound Rules no painel de detalhes inferior. Você deve ver que eles estão definidos como DENY para TODO o tráfego.
Verifique se você ainda está trabalhando na região primária, especialmente se estiver seguindo os links acima para abrir o console de serviço na tela certa.
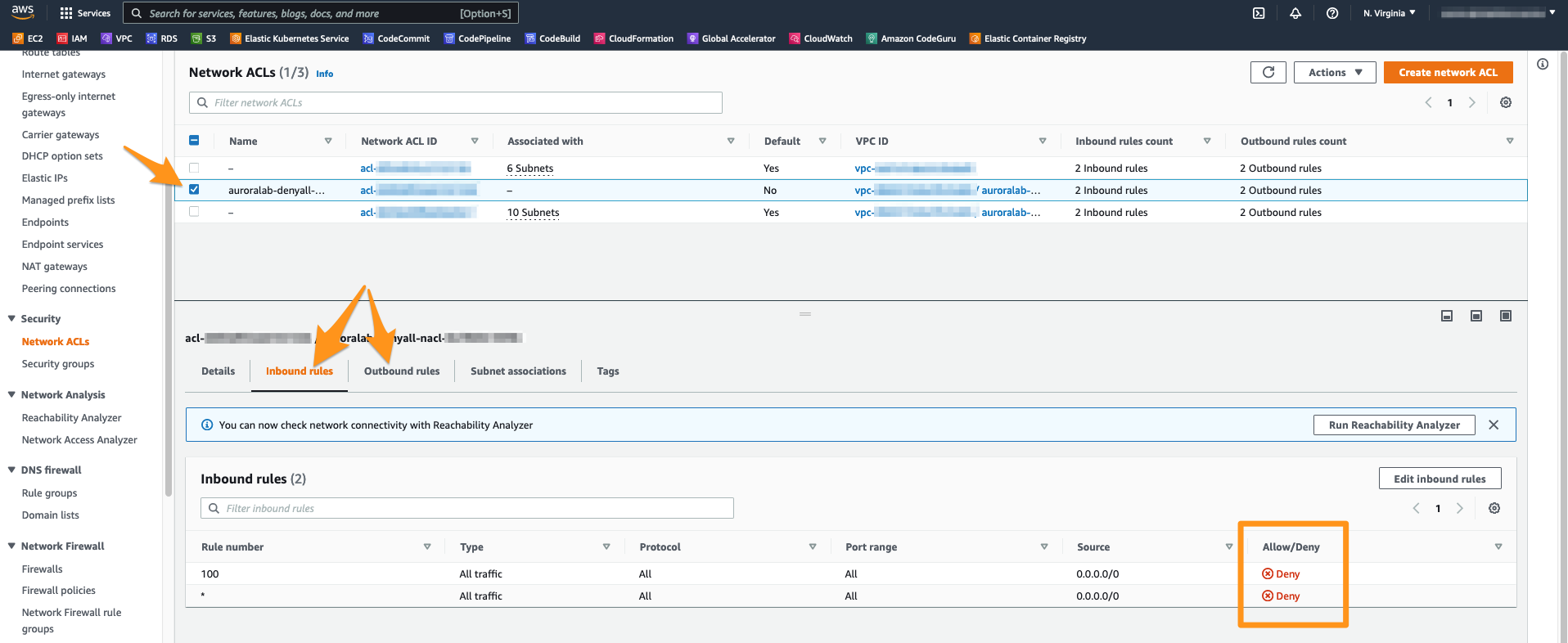
Alterne para a guia Subnet associations do NACL selecionado no painel de detalhes e clique no botão Edit subnet associations.
O cluster Aurora DB é configurado para usar as private subnets configuradas para seu ambiente de laboratório e gerenciadas pelo grupo de sub-rede RDS DB criado para seu ambiente de laboratório. Todas essas sub-redes são nomeadas com o prefixo auroralab-prv-sub-, seguido por um número correspondente à Zona de disponibilidade. Pode ser necessário ampliar a coluna Subnet ID para ver os nomes.
Selecione todas as sub-redes que começam com este prefixo auroralab-prv-sub-. Você também pode simplesmente usar a caixa de pesquisa para filtrar em qualquer sub-rede com o nome ** prv ** e selecioná-la. Em seguida, clique no botão Edit para confirmar as associações.
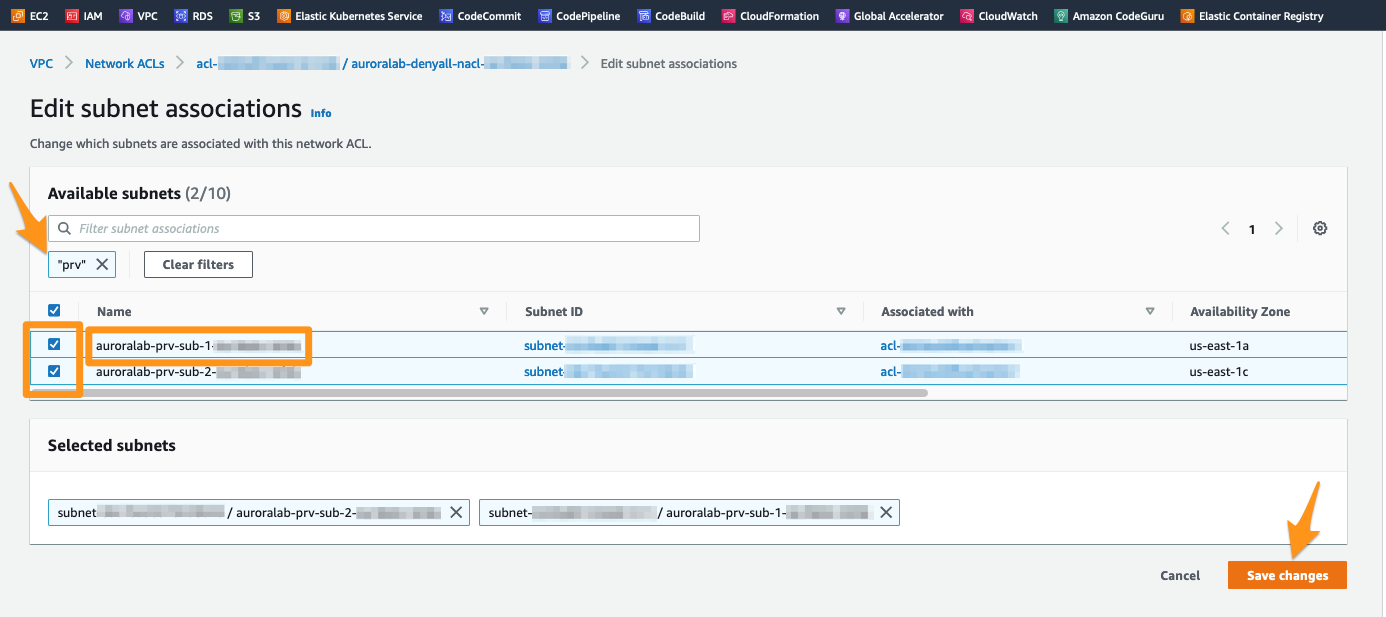
Uma vez associadas, as regras NACL entram em vigor imediatamente e tornarão os recursos dentro das sub-redes privadas inacessíveis. Sua conexão com o banco de dados na linha de comando do Session Manager deve eventualmente ser interrompida com uma mensagem de erro indicando que o cliente perdeu a conexão com o servidor.
2. Promova o cluster de banco de dados secundário
Você está simulando uma falha de nível de serviço ou infraestrutura regional prolongada; nesse ponto, você normalmente optaria por executar um failover regional em seu site de DR para suas aplicações e stacks de banco de dados. Em seguida, você promoverá o cluster de banco de dados secundário, na região secundária a um cluster de banco de dados regional independente.
Abra o console de serviço Amazon RDS na página de detalhes do cluster MySQL DB do cluster DB secundário.
Verifique se você está trabalhando na região secundária, especialmente se estiver seguindo os links acima para abrir o console de serviço na tela certa.
Por que o status do meu cluster de banco de dados primário e instância de banco de dados ainda aparecem como Available ?
Você também pode notar que em seu console RDS ele ainda mostrara o cluster de banco de dados da região primária e a instância de banco de dados como Available, isso porque você está apenas simulando uma falha bloqueando todo o acesso à rede por meio de NACLs e tal simulação é limitada apenas à sua conta AWS, especificamente ao seu VPC e suas sub-redes afetadas; o serviço RDS/Aurora e suas verificações de integridade internas são fornecidas pelo próprio serviço e ainda relatam o cluster de banco de dados e a instância de banco de dados como íntegros porque não há nenhuma interrupção real.
Com o cluster de banco de dados secundário auroralab-mysql-secondary selecionado, clique no menu Actions e selecione Remove from Global.
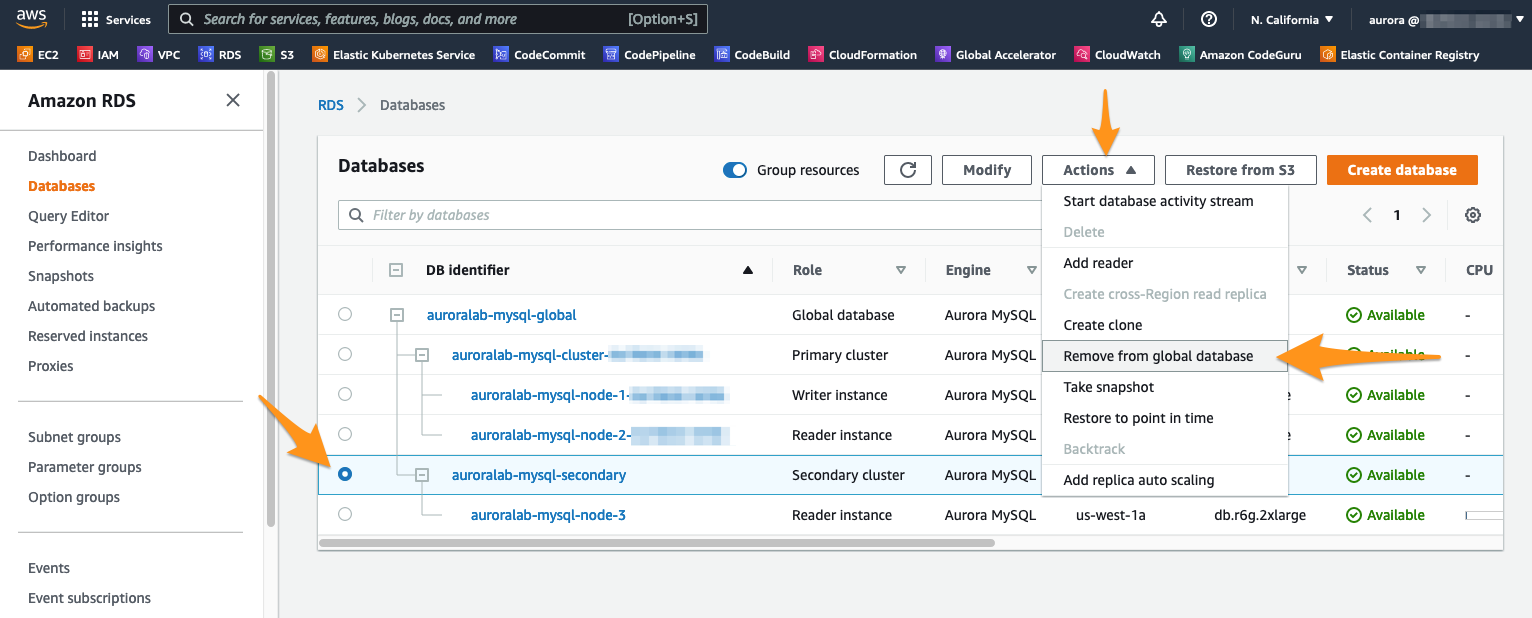
Uma mensagem aparecerá solicitando que você confirme. Essa ação interromperá a replicação do cluster de banco de dados primário. Confirme clicando em Remove and promote.

O processo de promoção deve levar menos de 1 minuto. Depois de concluído, você poderá ver que o cluster de banco de dados anteriormente secundário agora está rotulado como Regional e a instância de banco de dados agora é um nó de Writer.
Clique no cluster de banco de dados recém-promovido. Na guia Connectivity and security, o endpoint do Writer agora deve ser listado como Available. Copie e cole a string do terminal em seu bloco de notas.
Abra uma sessão adicional no Session Manager na região secundária. Consulte Conectar ao Session Manager, para obter o passo a passo de como criar uma sessão de linha de comando do Session Manager, mas certifique-se de usar a região secundária.
Verifique se você está trabalhando na região secundária, especialmente se estiver seguindo os links acima para abrir o console de serviço na tela certa.
Uma vez conectado, você precisa configurar as credenciais do banco de dados na estação de trabalho EC2 na região secundária. Se você criou o cluster de banco de dados primário original manualmente, realizou uma etapa semelhante naquele momento. Execute os seguintes comandos, substituindo os marcadores de posição por valores conforme indicado na tabela abaixo:
| Placeholder | Onde encontrar |
|---|---|
| ==[secretArn]== | Você o encontrará nas saídas da Stack do CloudFormation que você usou para provisionar o ambiente de laboratório. O valor começa com arn:aws:secretsmanager: |
| ==[primaryRegion]== | O identificador da região primária que você está usando, clique no nome no canto superior direito do console. Você o encontrará ao lado do nome, por exemplo us-east-2, embora sua região possa variar. |
CREDS=`aws secretsmanager get-secret-value --secret-id [secretArn] --region [primaryRegion] | jq -r '.SecretString'`
export DBUSER="`echo $CREDS | jq -r '.username'`"
export DBPASS="`echo $CREDS | jq -r '.password'`"
echo "export DBPASS=\"$DBPASS\"" >> /home/ubuntu/.bashrc
echo "export DBUSER=$DBUSER" >> /home/ubuntu/.bashrc
Em seguida, execute o comando abaixo, substituindo o marcador [newClusterEndpont] pelo endereço de conexão do cluster de banco de dados recém-promovido.
mysql -h[newClusterEndpoint] -u$DBUSER -p"$DBPASS" mylab
Uma vez conectado ao banco de dados, use o código abaixo para criar uma tabela. Execute as seguintes consultas SQL:
SELECT * FROM failovertest1;
Observe os resultados da consulta, isso deve retornar os valores que você inseriu no Banco de Dados pouco antes da falha simulada.
Insira um novo registro nesta tabela. Copie e cole a consulta a seguir e execute-a. Quais você espera que sejam os resultados?
INSERT INTO failovertest1 (gen_number, some_text, input_dt)
VALUES (200,"region-2-input",now());
SELECT * FROM mylab.failovertest1;
Sua aplicação agora pode atender consultas de leitura e gravação onde costumava ser sua região secundária e atender a seus usuários normalmente, durante uma interrupção em toda a região!
Removendo os labs
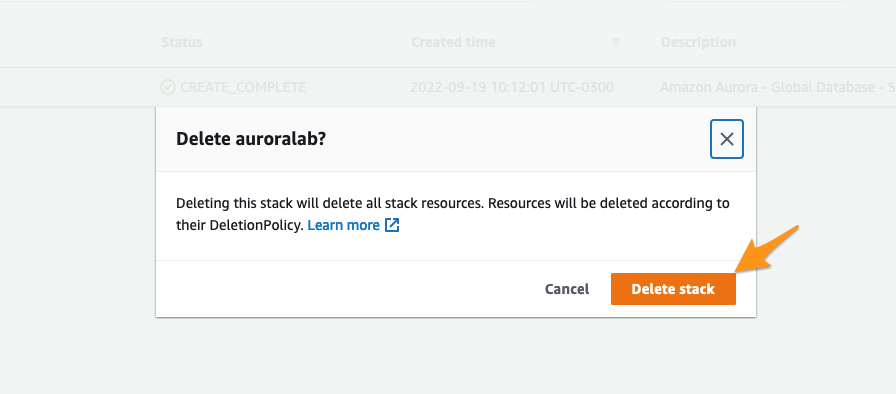
Para remover os ambientes de lab criados vá até o CloudFormation em cada região escolhida, selecione a stack utilizada nos laboratórios e escolha a opção Delete e depois confirme clicando em Delete stack.
Conclusão
Com esse exercício foi possível verificar como criar um Cluster Aurora Global, monitorar a atualização dos dados entre regiões e realizar o failover entre as regiões.
Fonte: Amazon Aurora Labs for MySQL