Estratégias para Recuperação de Desastres
Ter um plano de recuperação de desastres, é mais que ter rotinas de backups e componentes redundantes. Você deve definir quais os seus objetivos de RTO e RPO para recuperação de desastres. Defina os objetivos baseados nas métricas do negócio.
Defina objetivos, dentro do que é aceitável para sua aplicação, sobre tempo de downtime e perda de dados.
Definido o objetivo de tempo de recuperação (RTO) e objetivo de ponto de recuperação (RPO) para cada aplicação, você terá como guiar suas decisões sobre quais estratégias de recuperação de desastres seguir.

Objetivo de Tempo de Recuperação (RTO) é o atraso máximo aceitável entre a interrupção do serviço e a restauração do serviço. Isso determina o que é considerado uma janela de tempo aceitável quando o serviço está indisponível.
Objetivo de Ponto de Recuperação (RPO) é o tempo máximo aceitável desde o último ponto de recuperação de dados. Isso determina o que é considerado uma perda aceitável de dados entre o último ponto de recuperação e a interrupção do serviço.
Cada serviço possui um Acordo de Nível de Serviço (SLA). Caso esteja buscando um uptime superior ao definido pela AWS ou precise minimizar os riscos de falhas em um região, defina então uma estratégia de recuperação Multi-Region.
As estratégias podem ser definidas em diferentes níveis da sua arquitetura, como componentes de software, hardware, redes, zonas de disponibilidade, etc. Se necessário uma estratégia Multi-Region, você deve escolher uma das estratégias a seguir. Elas estão listadas em ordem crescente de complexidade, e decrescente de RTO e RPO.
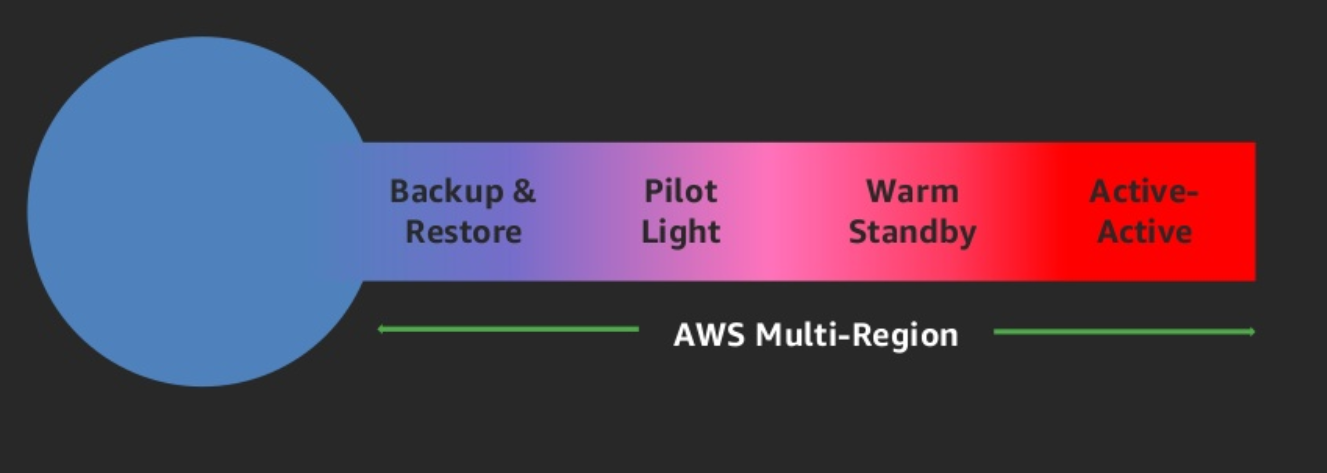
Backup & Restore (RPO em horas, RTO em 24 horas ou menos): faça backup de seus dados e aplicativos na região de DR. Restaure esses dados, quando necessário, para se recuperar de um desastre.
Pilot Light (RPO em minutos, RTO em horas): mantenha uma versão mínima de um ambiente sempre executando os elementos principais mais críticos do seu sistema na região de DR. No momento de executar a recuperação, você poderá provisionar rapidamente um ambiente de produção em escala completa que inclua esse núcleo crítico.
Warm Standby (RPO em segundos, RTO em minutos): mantenha uma versão reduzida de um ambiente totalmente funcional sempre em execução na região de DR. Os sistemas críticos para os negócios são totalmente duplicados e estão sempre ativados, mas com uma frota reduzida. Quando chega o momento da recuperação, o sistema é dimensionado rapidamente para processar a carga de produção.
Active-Active (RPO é nenhum ou possivelmente segundos, RTO em segundos): sua carga de trabalho é implantada e atende ativamente ao tráfego de várias regiões da AWS. Essa estratégia requer que você sincronize os usuários e dados entre as regiões que está usando. Quando chegar o momento da recuperação, use serviços como o Amazon Route 53 ou o AWS Global Accelerator para rotear o tráfego dos usuários ao local da carga de trabalho íntegra.
**Busque automatizar ao máximo todas as etapas dos seus testes:**
- Injeção de falhas no ambiente
- Ações de Failover (procedimento para uso do ambiente secundário)
- Ações de Failback (procedimento para o retorno do uso do ambiente primário)
- Monitoramento de todas as etapas
Evite mecanismos de recuperação que não são frequentemente testados. Defina testes regulares para o failover para garantir que o RTO e o RPO esperados sejam cumpridos
Referências: